Merino
Merino is a service that provides address bar suggestions and curated recommendations to Firefox. Some of this content comes from third party providers. In this case, Merino serves as a privacy preserving buffer. User input in the address bar is handled by Merino and any clicked impression will be delegated to a Mozilla-controlled service which will then send an interaction ping if defined in the request and not to a provider directly. See API documentation for more details.
Table of Contents
api.md - API Documentation describes endpoints, query parameters, request and response headers, response objects and details on the suggestion objects.
firefox.md - Firefox and Merino Environments describes how to enable Merino in Firefox and lists the endpoints for the service in Production, State and Dev.
data.md - Data, Metrics, Logging describes all metrics and logs.
dev/index.md - Basic Developer Docs describes basics of working on Merino.
dev/dependencies.md - Development Dependencies describes the development dependencies required for Merino.
dev/logging-and-metrics.md - Logging and Metrics describes metrics, logging, and telemetry.
dev/release-process.md - Release Process describes the release process of Merino in detail.
dev/testing.md - Testing describes unit, integration and load tests for Merino.
dev/profiling.md - Profiling describes how to profile Merino to address performance issues.
operations/configs.md - Configuring Merino describes configuration management of the project, Dynaconf setup, and the configuration of the HTTP server, logging, metrics, Remote Settings, and Sentry.
operations/elasticsearch.md - Elasticsearch Operations describes some functionality and operations that we do on the Elasticsearch cluster.
operations/jobs.md - Merino Jobs describes the jobs that are configured in Merino. Indicate where the jobs exist and link to the details for how the jobs are run.
About the Name
This project drives an important part of Firefox's "felt experience". That is, the feeling of using Firefox, hopefully in a delightful way. The word "felt" in this phrase refers to feeling, but it can be punned to refer to the textile. Felt is often made of wool, and Merino wool (from Merino sheep) produces exceptionally smooth felt.
Architecture
flowchart TD
subgraph Firefox["fa:fa-firefox-browser Firefox"]
NewTab
UrlBar
end
subgraph NewTab["fa:fa-plus New Tab"]
CuratedRecommendations("Curated Recommendations")
WeatherWidget("Weather Widget")
end
subgraph UrlBar["fa:fa-magnifying-glass Url Bar"]
online("Online Search and Suggest")
offline("Offline Search and Suggest<br>fetches adMarketplace, static Wikipedia, <br>and other suggestions.<br> Offline mode is fallback if Merino times out.")
end
subgraph middleware["fa:fa-layer-group Middleware"]
Geolocation["Geolocation"]
Logging["Logging"]
UserAgent["UserAgent"]
Metrics["Metrics"]
end
subgraph suggestProviders["fa:fa-truck Suggest Providers"]
admProvider("adm")
amoProvider("amo")
geolocationProvider("geolocation")
toppicksProvider("top-picks")
weatherProvider("weather")
wikipediaProvider("wikipedia")
financeProvider("finance")
end
subgraph suggestBackends["fa:fa-microchip Suggest Backends"]
remoteSettingsBackend("remote settings")
accuweatherBackend("accuweather")
elasticBackend("elastic")
toppicksBackend("top picks")
dynamicAmoBackend("dynamic addons")
polygonBackend("polygon")
end
subgraph curatedRecommendationsBackends["fa:fa-microchip Curated Recommendations Backends"]
corpusBackend("corpus")
extendedExpirationCorpusBackend("corpus extended expiration")
gcsEngagementBackend("gcs engagement")
gcsPriorBackend("gcs prior")
spindleBackend("spindle ML server")
end
subgraph Merino["fa:fa-server Merino"]
srh("fa:fa-gears Suggest Request Handler")
crh("fa:fa-gears Curated Recommendations Handler")
mrh("fa:fa-gears Manifest Handler")
middleware
maxmind[("fa:fa-database MaxmindDB")]
suggestProviders
curatedRecommendationsProvider["fa:fa-truck Curated Recommendations Provider"]
manifestProvider["fa:fa-truck Manifest Provider"]
suggestBackends
curatedRecommendationsBackends
manifestBackend["Manifest Backend"]
end
subgraph Jobs["fa:fa-rotate Airflow (Merino Jobs)"]
wikipediaSyncJob("Wikipedia Sync")
toppicksSyncJob("Top Picks Sync")
end
User[\"fa:fa-user User"/] -- Accessing the Firefox URL bar --> Firefox
online -- /api/v1/suggest --> srh
CuratedRecommendations -- "/api/v1/curated-recommendations" --> crh
manifest["manifest"] -- /api/v1/manifest --> mrh
WeatherWidget --> srh
srh -..- middleware
crh -..- middleware
mrh -..- middleware
srh --> suggestProviders
crh --> curatedRecommendationsProvider
mrh --> manifestProvider
curatedRecommendationsProvider --> curatedRecommendationsBackends
manifestProvider --> manifestBackend
admProvider --> remoteSettingsBackend
amoProvider --> dynamicAmoBackend
toppicksProvider --> toppicksBackend
weatherProvider --> accuweatherBackend
wikipediaProvider --> elasticBackend
financeProvider --> polygonBackend
polygonBackend --> polygonApi("fa:fa-globe Polygon API")
Geolocation --> maxmind
dynamicAmoBackend --> addonsAPI("fa:fa-globe Addons API")
elasticBackend --> elasticSearch[("Elasticsearch")]
manifestBackend -..-> toppicksData[("fa:fa-database GCS Top Picks Data,<br>a list of Mozilla curated popular sites and metadata to be <br>displayed on browser")]
toppicksSyncJob -..-> toppicksData
accuweatherBackend -..-> accuweatherAPI("fa:fa-globe Accuweather API")
accuweatherAPI -. tries to query cache first ..-> redis[("fa:fa-memory Redis Cache")]
gcsEngagementBackend --> gcsMerinoAirflowData[("fa:fa-database GCS Merino Airflow Data")]
gcsPriorBackend --> gcsMerinoAirflowData
corpusBackend -..-> curatedCorpusAPI("fa:fa-globe Curated Corpus API")
spindleBackend -..-> spindleService("fa:fa-globe Spindle ML server<br>near-duplicate story embeddings")
offline -..- kinto[("Remote Settings")]
remoteSettingsBackend --- merinoRustExtension("fa:fa-puzzle-piece Merino Rust Extension")
merinoRustExtension --> kinto
wikipediaSyncJob -. Syncs Wikipedia entries weekly ..- elasticSearch
Merino API documentation
This page describes the API endpoints available on Merino.
The autogenerated API documentation exists here.
Working with the Manifest endpoint
Overview
The /manifest endpoint returns a curated list of websites with associated metadata. This endpoint is designed to be used as part of your development process to maintain an up-to-date copy of website favicons.
Endpoint details
- URL:
https://merino.services.mozilla.com/api/v1/manifest - Method:
GET - Response:
JSON
{
"domains": [
{
"rank": 1,
"domain": "google",
"categories": [
"Search Engines"
],
"serp_categories": [
0
],
"url": "https://www.google.com/",
"title": "Google",
"icon": ""
},
{
"rank": 2,
"domain": "microsoft",
"categories": [
"Business",
"Information Technology"
],
"serp_categories": [
0
],
"url": "https://www.microsoft.com/",
"title": "Microsoft – AI, Cloud, Productivity, Computing, Gaming & Apps",
"icon": "https://merino-images.services.mozilla.com/favicons/90cdaf487716184e4034000935c605d1633926d348116d198f355a98b8c6cd21_17174.oct"
}
]
}
The icon field has the url of the Mozilla-hosted favicon of the website.
Usage
- You can save the JSON response as a
manifest.jsonfile:
curl https://merino.services.mozilla.com/api/v1/manifest -o manifest.json
Or, if you have jq installed on your system, you can pretty-print it:
curl -s https://merino.services.mozilla.com/api/v1/manifest | jq '.' > manifest.json
- Check it into your repository and ship it with the application you are building.
- Whenever you need to display a favicon for a website or URL, you can check the
Manifestfile and use theiconfield as a link to the favicon.
Add custom domains
You are also able to add custom domains to this endpoint. We currently run a weekly cron job to collect favicons from the Top 2000 websites. Adding custom domains is handled via this Python file in the Merino codebase: https://github.com/mozilla-services/merino-py/blob/main/merino/jobs/navigational_suggestions/custom_domains.py
To add yours:
git clone git@github.com:mozilla-services/merino-py.git- Add a new entry to the
CUSTOM_DOMAINSlist withurland at least onecategory: https://github.com/mozilla-services/merino-py/blob/main/merino/jobs/navigational_suggestions/custom_domains.py - Create a PR against the
merino-pyrepo with your changes
The custom domains will be picked up during the next run (every Wednesday). This job can also be run manually by following instructions here.
Add custom favicons
Some websites block automated scrapers or have unreliable favicon detection. For these domains, you can specify a direct favicon URL that will be used instead of attempting to scrape it.
What are custom favicons?
Custom favicons are pre-defined favicon URLs stored in merino/jobs/navigational_suggestions/enrichments/custom_favicons.py. When the job processes a domain, it checks this file first before attempting to scrape the favicon. This ensures reliable favicon delivery for domains that would otherwise fail.
Where is this file used?
The CUSTOM_FAVICONS dictionary is imported and used by the domain processor (processing/domain_processor.py) during the favicon extraction phase. If a domain is found in the custom favicons mapping, the job will:
- Download the specified favicon URL
- Upload it to the CDN
- Skip the web scraping step entirely for that domain's favicon
Adding custom favicons with the CLI (Recommended)
The easiest way to add custom favicons is using the probe-images command-line tool. This tool will automatically test a domain, find the best favicon, and save it to the CUSTOM_FAVICONS dictionary.
Basic usage:
# Test a domain and save its best favicon
probe-images example.com --save
With options:
# Specify minimum favicon width (default is 32px)
probe-images example.com --save --min-width 64
# Test multiple domains at once
probe-images example.com mozilla.org github.com --save
What the CLI does:
When you run probe-images with the --save flag, it will:
- Scrape the domain and extract all available favicons
- Apply the same selection logic used in production to find the best favicon
- Automatically update
merino/jobs/navigational_suggestions/enrichments/custom_favicons.py - Add the domain (without TLD) as the key and the best favicon URL as the value
Example output:
Testing domain: mozilla.org
✅ Success!
Title Internet for people, not profit — Mozilla Global
Best Icon https://www.mozilla.org/media/img/favicons/mozilla/favicon-196x196.png
Total Favicons 5
All favicons found:
- https://www.mozilla.org/media/img/favicons/mozilla/apple-touch-icon.png (rel=apple-touch-icon size=180x180)
- https://www.mozilla.org/media/img/favicons/mozilla/favicon-196x196.png (rel=icon size=196x196)
- https://www.mozilla.org/media/img/favicons/mozilla/favicon.ico (rel=shortcut,icon)
Save Results:
Saved Domain mozilla
Saved URL https://www.mozilla.org/media/img/favicons/mozilla/favicon-196x196.png
Save PATH merino/jobs/navigational_suggestions/enrichments/custom_favicons.py
Summary: 1/1 domains processed successfully
Adding custom favicons manually
You can also manually edit the CUSTOM_FAVICONS dictionary if you already know the favicon URL:
git clone git@github.com:mozilla-services/merino-py.git- Edit
merino/jobs/navigational_suggestions/enrichments/custom_favicons.py - Add a new entry to the
CUSTOM_FAVICONSdictionary:
CUSTOM_FAVICONS: dict[str, str] = {
"axios": "https://static.axios.com/icons/favicon.svg",
"espn": "https://a.espncdn.com/favicon.ico",
"yoursite": "https://yoursite.com/path/to/favicon.png", # Add your domain here
# ...
}
Important notes:
- Use the second-level domain name without the TLD (e.g., use
"mozilla"not"mozilla.org") - Use the direct URL to the favicon file
- Ensure the URL is publicly accessible and won't break over time
- Create a PR against the
merino-pyrepo with your changes
The custom favicons will be used during the next job run (every Wednesday), or can be triggered manually.
Configuring Firefox and Merino Environments
Merino has been enabled by default in Firefox. Though, you will need to enable
the data sharing for Firefox Suggest to fully enable the feature. To enable it,
type about:config in the URL bar set the Firefox preference
browser.urlbar.quicksuggest.dataCollection.enabled to true. By default,
Merino will connect to the production environments. This is controlled with the
browser.urlbar.merino.endpointURL preference. See below for other options.
You can also query any of the endpoint URLs below with something like:
curl 'https://merino.services.allizom.org/api/v1/suggest?q=your+query'
Environments
Production
Endpoint URL: https://merino.services.mozilla.com/api/v1/suggest
The primary environment for end users. Firefox is configured to use this by default.
Stage
Endpoint URL: https://merino.services.allizom.org/api/v1/suggest
This environment is used for manual and load testing of the server. It is not guaranteed to be stable or available. It is used as a part of the deploy process to verify new releases before they got to production.
Data collection
This page should list all metrics and logs that Merino is expected to emit in production, including what should be done about them, if anything.
Logs
This list does not include any DEBUG level events, since those are not logged
by default in production. The level and type of the log is listed.
Any log containing sensitive data must include a boolean field sensitive
that is set to true to exempt it from flowing to the generally accessible
log inspection interfaces.
Merino APIs
-
INFO web.suggest.request- A suggestion request is being processed. This event will include fields for all relevant details of the request. Fields:sensitive- Always set to true to ensure proper routing.query- If query logging is enabled, the text the user typed. Otherwise an empty string.country- The country the request came from.region- The first country subdivision the request came from.city- The city the request came from.dma- A US-only location description that is larger than city and smaller than states, but does not align to political borders.agent- The original user agent.os_family- Parsed from the user agent. One of "windows", "macos", "linux", "ios", "android", "chrome os", "blackberry", or "other".form_factor- Parsed from the user agent. One of "desktop", "phone", "tablet", or "other"browser- The browser and possibly version detected. Either "Firefox(XX)" where XX is the version, or "Other".rid- The request ID.- WIP
accepts_english- True if the user's Accept-Language header includes an English locale, false otherwise. requested_providers- A comma separated list of providers requested via the query string, or an empty string if none were requested (in which case the default values would be used).client_variants- Any client variants sent to Merino in the query string.session_id- A UUID generated by the client for each search session.sequence_no- A client-side event counter (0-based) that records the query sequence within each search session.
ERROR dockerflow.error_endpoint- The__error__endpoint of the server was called. This is used to test our error reporting system. It is not a cause for concern, unless we receive a large amount of these records, in which case some outside service is likely malicious or misconfigured.
Merino Middleware Logs
Geolocation
WARNING merino.middleware.geolocation- There was an error with a geolocation lookup.
Merino Cron Tasks
WARNING merino.cron- There was an error while executing a cron task.
Merino Feature Flags
ERROR merino.featureflags- There was an error while attempting to assign a feature flag for a suggest API request.
Curated Recommendations
ERROR merino.curated_recommendations.corpus_backends.corpus_api_backend- Failed to get timezone for scheduled surface.WARNING merino.curated_recommendations.corpus_backends.corpus_api_backend- Retrying CorpusApiBackend after an http client exception was raised.ERROR GcsEngagement failed to update cache: {e}- unexpected exception when updating engagement.ERROR Curated recommendations engagement size {blob.size} > {self.max_size}- Max engagement blob size is exceeded. The backend will gracefully fall back to cached data or 0's.INFO Curated recommendations engagement unchanged since {self.last_updated}.- The engagement blob was not updated since the last check.last_updatedis expected to be between 0 and 30 minutes.
Metrics
[!NOTE] Metric documentation has been moved to metrics.yaml. Please use that to document all the new metrics. This section now serves as the legacy metrics document only.
A note on timers: Statsd timers are measured in milliseconds, and are reported as integers (at least in Cadence). Milliseconds are often not precise enough for the tasks we want to measure in Merino. Instead, we use generic histograms to record microsecond times. Metrics recorded in this way should have
-usappended to their name, to mark the units used (since we shouldn't put the proper unit μs in metric names).
-
merino.<http_method>.<url_path>.status_codes.<status_code>- A counter to measure the status codes of an HTTP method for the<url_path>.Example:
merino.get.api.v1.suggest.status_codes.200 -
merino.<http_method>.<url_path>.timing- A timer to measure the duration (in ms) of an HTTP method for a URL path.Example:
merino.get.api.v1.suggest.timing -
merino.<provider_module>.query- A timer to measure the query duration (in ms) of a certain suggestion provider.Example:
merino.providers.suggest.adm.query -
merino.<provider_module>.query.timeout- A counter to measure the query timeouts of a certain suggestion provider.Example:
merino.providers.suggest.wikipedia.query.timeout -
merino.suggestions-per.request- A histogram metric to get the distribution of suggestions per request. -
merino.suggestions-per.provider.<provider_module>- A histogram metric to get the distribution of suggestions returned per provider (per request).Example:
merino.suggestions-per.provider.wikipedia
AccuWeather
The weather provider records additional metrics.
accuweather.upstream.request.<request_type>.get- A counter to measure the number of times an upstream request to Accuweather was made.accuweather.request.location.not_provided- A counter to measure the number of times a query was send without a location being provided, and therefore unable to process a weather request. Sampled at 75%.accuweather.request.location.dist_calculated.success- A counter to measure the number of successful lat long distance calculations used to find location.accuweather.request.location.dist_calculated.fail- A counter to measure the number of failed lat long distance calculations used to find location.merino.providers.accuweather.query.cache.fetch- A timer to measure the duration (in ms) of looking up a weather report in the cache. Sampled at 75%.merino.providers.accuweather.query.cache.fetch.miss.locations- A counter to measure the number of times weather location was not in the cache. Sampled at 75%.merino.providers.accuweather.query.cache.fetch.miss.currentconditions- A counter to measure the number of times a current conditions was not in the cache. Sampled at 75%.merino.providers.accuweather.query.cache.fetch.miss.forecasts- A counter to measure the number of times a forecast for a location was not in the cache. Sampled at 75%.merino.providers.accuweather.query.cache.fetch.hit.{locations | currentconditions | forecasts}- A counter to measure the number of times a requested value like a location or forecast is in the cache. We don't count TTL hits explicitly, just misses. Sampled at 75%.merino.providers.accuweather.query.backend.get- A timer to measure the duration (in ms) of a request for a weather report from the backend. This metric isn't recorded for cache hits. Sampled at 75%.merino.providers.accuweather.query.cache.store- A timer to measure the duration (in ms) of saving a weather report from the backend to the cache. This metric isn't recorded for cache hits. Sampled at 75%.merino.providers.accuweather.query.cache.error- A counter to measure the number of times the cache store returned an error when fetching or storing a weather report. This should be 0 in normal operation. In case of an error, the logs will include aWARNINGwith the full error message.merino.providers.accuweather.query.weather_report- A counter to measure the number of queries that are for weather, origin of the request is recorded in tags.merino.providers.accuweather.skip_cities_mapping.total.size- A counter to measure the total number of occurrences cities were skipped due to no locationmerino.providers.accuweather.skip_cities_mapping.unique.size- A counter to measure the number of unique cities that are skipped due to no location
Curated Recommendations
The following additional metrics are recorded when curated recommendations are requested.
corpus_api.{get_sections | scheduled_surface}.timing- A timer to measure the duration (in ms) of making a request to the Corpus API.corpus_api.{get_sections | scheduled_surface}.status_codes.{res.status_code}- A counter to measure the status codes of an HTTP request to the curated-corpus-api.corpus_api.{get_sections | scheduled_surface}.graphql_error- A counter to measure the number of GraphQL errors from the curated-corpus-api.recommendation.engagement.update.timing- A timer to measure the duration (in ms) of updating the engagement data from GCS.recommendation.engagement.size- A gauge to track the size of the engagement blob on GCS.recommendation.engagement.count- A gauge to measure the total number of engagement records.recommendation.engagement.{country}.count- A gauge to measure the number of scheduled corpus items with engagement data per country.recommendation.engagement.{country}.clicks- A gauge to measure the number of clicks per country in our GCS engagement blob.recommendation.engagement.{country}.impressions- A gauge to measure the number of impressions per country in our GCS engagement blob.recommendation.engagement.last_updated- A gauge for the staleness (in seconds) of the engagement data, measured between when the data was updated in GCS and the current time.recommendation.prior.update.timing- A timer to measure the duration (in ms) of updating the prior data from GCS.recommendation.prior.size- A gauge to track the size of the Thompson sampling priors blob on GCS.recommendation.prior.last_updated- A gauge for the staleness (in seconds) of the prior data, measured between when the data was updated in GCS and the current time.recommendation.ml.contextual.update.timing- A timer to measure the duration (in ms) of updating the engagement data from GCS.recommendation.ml.contextual.size- A gauge to track the size of the engagement blob on GCS.recommendation.ml.contextual.last_updated- A gauge for the staleness (in seconds) of the contextual engagement data, measured between when the data was updated in GCS and the current time.recommendation.ml.cohort_model.update.timing- A timer to measure the duration (in ms) of updating the cohort model data from GCS.recommendation.ml.cohort_model.size- A gauge to track the size of the cohort model blob on GCS.recommendation.ml.cohort_model.last_updated- A gauge for the staleness (in seconds) of the cohort model data, measured between when the data was updated in GCS and the current time. This value could get large as the model may be updated weekly.
Spindle ML server
Merino calls the Spindle ML server to find near-duplicate stories so the
article balancer can drop them from Popular Today. Each section fetch triggers
a background refresh of the per-surface similarity cache; the metrics below
are emitted from merino/curated_recommendations/ml_backends/spindle_backend.py.
recommendation.spindle.{text | image}.timing- A timer to measure the duration (in ms) of a request to the Spindle/find_similar_stories(text) or/find_similar_images(image) endpoint.recommendation.spindle.{text | image}.status_codes.{res.status_code}- A counter to measure the HTTP status codes returned by Spindle.recommendation.spindle.{text | image}.error- A counter incremented when the Spindle call raises an HTTP error or the response cannot be parsed. The previous cached similarity info is left in place when this fires.
Manifest
When requesting a manifest file, we record the following metrics.
manifest.request.get- A counter for how many requests against the/manifestendpoint where made.manifest.request.timing- A timer for how long it took the endpoint to fulfill the request.manifest.gcs.fetch_time- A timer for how long it took to download the latest manifest file from the Google Cloud bucket.manifest.request.no_manifest- A counter to measure how many times we didn't find the latest manifest file.manifest.request.error- A counter to measure how many times we could not provide a valid JSON manifest file.manifest.invalid_icon_url- A counter to measure how many requests the Manifest provider gets for domains where we don't have a valid icon Url (with tags).
Service Governance
The following metrics are recorded for service governance monitoring.
governance.circuits.<circuit-breaker-name>- A gauge to instrument the failure count for each "open" circuit breaker.
Merino Developer Guidelines and Social Contract
This is an additional contractual document on top of CONTRIBUTING.
Foster a Shared Ownership
Not only do Merino developers build the service together, they also share the ownership of the service. That ownership is embodied in the following responsibilities:
- Be responsible for the entire lifecycle of each change landed in the code base: from writing the PR and getting it merged; ensuring it goes through CI/CD and eventually deployed to production; setting up monitoring on metrics and ensuring its healthy status and the overall health of Merino.
- Be familiar with Merino’s operation. Conduct operational reviews on a regular basis. Identify and track operational issues. Coordinate with the team(s) to close action items and resolve the identified issues.
- Documentation. Make sure the code meets the documentation requirements (no linting errors). If a change adds/updates the API, logs or metrics, ensure the associated documentation is up to date.
We commit to sharing knowledge about Merino across the team, with the long-term goal that each team member is capable of resolving incidents of Merino. Merino developers should familiarize themselves with the Mozilla Incident Response Process and the Merino Runbooks. Each individual should be able to initiate an incident response, serve as the incident handling manager, and drive it to its resolution along with other incident responders. Any issues associated with an incident should be tracked in Jira in a way the team agrees upon. For example, assigned with an ‘incident-action-items’ label.
- Be aware of the infrastructure costs associated with new functionality. The team should have a good understanding of the cost to run the service including logging, computing, networking, and storage costs.
- Be mindful of work hours and the time zones of your fellow developers when scheduling meetings, deploying code, pairing on code, or collaborating in other ways. Set your work hours in Google Calendar and configure Slack to receive notifications only during those times. We encourage code deployments when there are fellow developers online to support. If you must deploy off-hours, ensure you have a peer available to approve any potential rollbacks.
We are not going to grow individual Merino developers in deployment, operation, documentation, and incident responding for Merino. Rather, we’d like to foster a shared ownership with shared knowledge in every aspect of the day-to-day job for Merino.
Use ADRs to Record Architectural Decisions
ADRs (Architectural Decision Record) are widely adopted by teams at Mozilla to capture important architecture decisions, including their context and consequences. Developers are encouraged to exercise the ADR process to facilitate the decision making on important subjects of the project. ADRs should be made easy to access and reference and therefore are normally checked into the source control and rendered as part of the project documentation.
Use SLO and Error Budget to Manage Service Risks
We strive to build highly available and reliable services while also emphasizing rapid iteration and continuous deployment as key aspects of product development. We opt to use SLOs (Service Level Objective) and error budget for risk management. SLOs can be co-determined by the product owner(s) and the service builders & operators. The error budget should be monitored and enforced by the monitoring infrastructure. Once the budget is reached, the service owners should be more reluctant or even reject to accept risky code artifacts until the budget gets reset.
Request RRA for New Content Integrations
RRA (Rapid Risk Assessment) is the recommended process for service builders to perform a standardized lightweight risk assessment for the service or the feature of interest. Since Merino is a user-facing consumer service, we shall take extra caution for user security and the related risks. We have agreed with the Security Assurance team that we’d request an RRA (by following the RRA instructions) for every new content integration (e.g. AccuWeather) or content storage (e.g. Elasticsearch) for Merino.
Testing for Productivity & Reliability
We value testing as a mechanism of establishing feedback loops for service development, design, and release. As developers add new changes to the project, thorough and effective testing reduces uncertainty and generates short feedback loops, accelerating development, release, and regression resolution. Testing also helps reduce the potential decrease in reliability from each change. To materialize those merits for Merino, we have designed the Merino Test Strategy and fulfilled it with adequate tests. We anticipate the cross-functional team to adhere to the strategy and evolve it to better support the project over time.
Aim for Simplicity
We prioritize simple and conventional solutions in all aspects of development, from system design, to API specs, to code. We prefer mature, battle-tested technologies over complex, cutting-edge alternatives. At the same time, we know that Merino can always get better, and we welcome ideas from everyone. If you’ve got a new approach in mind, share it with the team or propose an Architectural Decision Record (ADR).
Blame-free Culture
While we strive to make Merino a highly reliable service, things would still go wrong regardless of how much care we take. Code errors, misconfigurations, operational glitches, to name a few. We opt for a blame-free culture to ease the mental stress when individuals are encouraged to take on more activities & responsibilities, especially before they gain familiarity around the tasks. We believe that learning from mistakes and incorporating the learned experience into processes to avoid repeating the same mistakes is more constructive and useful than putting someone on center stage. With a blame-free culture and proper risk management processes in place, the average cost of failures should be more tolerable within the error budget boundary. Who would be afraid of making mistakes?
Have Fun
Last but not least. Let’s make Merino a fun project to work with!
Developer documentation for working on Merino
tl;dr
Here are some useful commands when working on Merino.
Run the main app
This project uses uv for dependency management. See dependencies for how to install uv on your machine.
Install all the dependencies:
uv sync --all-groups --all-packages
Run Merino:
$ uv run fastapi run merino/main.py --reload
# Or you can use a shortcut
$ make run
# To run in hot reload mode
$ make dev
General commands
# List all available make commands with descriptions
$ make help
$ make install
# Run linter
$ make ruff-lint
# Run format checker
$ make ruff-fmt
# Run formatter
$ make ruff-format
# Run black
$ make black
# Run bandit
$ make bandit
# Run mypy
$ make mypy
# Run all linting checks
$ make -k lint
# Run all formatters
$ make format
# Run merino-py with the auto code reloading
$ make dev
# Run merino-py without the auto code reloading
$ make run
# Run unit and integration tests and evaluate combined coverage
$ make test
# Evaluate combined unit and integration test coverage
$ make test-coverage-check
# Run unit tests
$ make unit-tests
# List fixtures in use per unit test
$ make unit-test-fixtures
# Run integration tests
# (assumes prebuilt elasticsearch image)
$ make integration-tests
# Run integration tests locally
# (builds custom elasticsearch image)
$ make integration-tests-local
# List fixtures in use per integration test
$ make integration-test-fixtures
# Build the docker image for Merino named "app:build"
$ make docker-build
# Run local execution of (Locust) load tests
$ make load-tests
# Stop and remove containers and networks for load tests
$ make load-tests-clean
# Generate documents
$ make doc
# Preview the generated documents
$ make doc-preview
# Profile Merino with Scalene
$ make profile
# Run the Wikipedia CLI job
$ make wikipedia-indexer job=$JOB
Documentation
You can generate documentation, both code level and book level, for Merino and
all related crates by running ./dev/make-all-docs.sh. You'll need mdbook
and mdbook-mermaid, which you can install via:
make doc-install-deps
If you haven't installed Rust and Cargo, you can reference the official Rust document.
Local configuration
The default configuration of Merino is development, which has human-oriented
pretty-print logging and debugging enabled. For settings that you wish to change in the
development configuration, you have two options, listed below.
For full details, make sure to check out the documentation for Merino's setting system (operations/configs.md).
Update the defaults
Dynaconf is used for all configuration management in Merino, where
values are specified in the merino/configs/ directory in .toml files. Environment variables
are set for each environment as well and can be set when using the cli to launch the
Merino service.
Environment variables take precedence over the values set in the .toml files, so
any environment variable set will automatically override defaults. By the same token,
any config file that is pointed to will override the merino/configs/default.toml file.
If the change you want to make makes the system better for most development
tasks, consider adding it to merino/configs/development.toml, so that other developers
can take advantage of it. If you do so, you likely want to add validation to those settings
which needs to be added in merino/config.py, where the Dynaconf instance exists along
with its validators. For examples of the various config settings, look at configs/default.toml
and merino/config.py to see an example of the structure.
It is not advisable to put secrets in configs/secrets.toml.
Create a local override
Dynaconf will use the specified values and environment variables in the
merino/configs/default.toml file. You can change the environment you
want to use as mentioned above, but for local changes to adapt to your
machine or tastes, you can put the configuration in merino/configs/development.local.toml.
This file doesn't exist by default, so you will have to create it.
Then simply copy from the other config files and make the adjustments
that you require. These files should however not be checked into source
control and are configured to be ignored, so long as they follow the *.local.toml
format. Please follow this convention and take extra care to not check them in
and only use them locally.
See the Dynaconf Documentation for more details.
Content Moderation and Blocklists
This summarizes the mechanisms that block sensitive or questionable content in Merino. Because Merino supports several providers that have a broad range of potential suggestions, often from different sources, we require the ability to remove certain suggestions from being displayed.
Blocklists in Merino filter content at two distinct phases:
-
Content that is filtered at the data creation and indexing phase. Provider backends serve suggestions to the client based on matching against searched terms. This ensures that data that could be sensitive is not available to search against since it is not indexed. For instance, the Wikipedia provider filters categories of articles that are tagged with a matching category term in the blocklist.
-
Content that is filtered at application runtime. There are instances where we want to quickly and dynamically add to block lists without re-indexing or running a job. In this case, suggestions are compared to a static list in the code that blocks out these suggestions.
Navigational Suggestions / Top Picks
In the Navigational Suggestions provider, a blocklist is used during data creation to block specific domains of websites that we do not want to suggest.
The blocklist, domain_blocklist.json, is referenced during data generation of the top_picks.json file, which is ingested by the provider backend. This ensures specific domains are not indexed for suggestions. The blocklist is loaded and an exact string comparison is made between all second-level domains and the second-level domains defined in the blocklist.
See nav-suggestions blocklist runbook for more information.
Wikipedia
The Wikipedia Provider does both title filtering and category filtering at the data indexing level.
Since the indexing jobs run periodically, we also implemented title filtering in the provider to get the blocking out sooner.
Indexer
The Wikipedia Indexer Job references a remote blocklist which contains sensitive categories. At job runtime, the indexer reads the remote blocklist and creates a set of article categories that are be excluded from indexing.
The article categories in the blocklist are chosen based off of analysis and best guesses of what could be considered objectionable content, based off of Mozilla's values and brand image. Any modifications to the file should be done with careful consideration.
The indexer also blocks titles that are defined in the WIKIPEDIA_TITLE_BLOCKLIST in the application, which is referenced below. Any title that matches this blocklist is excluded from indexing.
Provider
When queried, the Wikipedia provider reads the WIKIPEDIA_TITLE_BLOCKLIST when creating a WikipediaSuggestion and if the query matches a blocked title, the suggestion is not shown to the client.
We have this feature because the indexing job is not run daily. Therefore, we desire having an option to rapidly add to this list should we need to block a specific article.
See wikipedia blocklist runbook for more information.
Development Dependencies
Package Dependencies
This project uses uv for dependency management, virtual environment management and running scripts and commands.
While you can use the vanilla virtualenv to set up the dev environment, we highly recommend to check
out uv.
To install uv, run:
$ pipx install uv
Or install via your preferred method.
Feel free to browse the pyproject.toml file for a listing of dependencies and their versions.
First, lets make sure you have a virtual environment set up with the right Python version. This service uses Python 3.13.
$ uv venv
See more about setting up virtual envs and Python version with uv.
Once uv is installed, and a virtual environment is created with the correct Python version, install all the dependencies:
$ uv sync --all-groups --all-packages
Add packages to project via uv
$ uv add <package_name>
After that you should be to run Merino as follows:
$ uv run fastapi run merino/main.py --reload
Moving from the Poetry & Pyenv Set up
If you had your environment previously set up via poetry and pyenv, here are the steps to move to uv. This would be a nice clean up and reset.
# Remove your previous virtual environment. If you set up using pyenv, then:
rm .python-version
pyenv uninstall merino-py
# Uninstall pyenv
rm -rf $(pyenv root)
# or if you installed it via your OS package manager
brew uninstall pyenv
Service Dependencies
Merino uses a Redis-based caching system, and so requires a Redis instance to
connect to. In addition, a GCS (GCP Cloud Storage) emulator, fake-gcs-server,
is also provided to facilitate local development and testing.
To make things simple, all these service dependencies can be started with Docker
Compose, using the docker-compose.yaml file in the dev/ directory.
Notably, this does not run any Merino components that have source
code in this repository.
# Run this at the Merino's project root
$ docker compose -f dev/docker-compose.yaml up
# Or run services in deamon mode
$ docker compose -f dev/docker-compose.yaml up -d
# Stop it
$ docker compose -f dev/docker-compose.yaml down
# Shortcuts are also provided
$ make docker-compose-up
$ make docker-compose-up-daemon
$ make docker-compose-down
Redis
Two Redis servers (primary & replica) are listening on ports 6379 and 6380,
and can be connected via redis://localhost:6379 and redis://localhost:6380,
respectively.
This Dockerized set up is optional. Feel free to run the dependent services by any other means as well.
GCS Emulator
The GCS emulator is listening on port 4443 and ready for both read and write
operations. Make sure you set a environment variable STORAGE_EMULATOR_HOST=http://localhost:4443
so that Merino's GCS clients can connect to it. For example,
$ STORAGE_EMULATOR_HOST=http://localhost:4443 make run
Optionally, you can create a GCS bucket and preload data into it. The preloaded
data is located in dev/local_setup/gcs/. Say if you want to preload
a JSON file top_picks_latest.json into a bucket merino-images-prodpy, you
can create a new sub-directory merino-images-prody in gcs and then
create or copy top_picks_latest.json into it. Then you can set Merino's
configurations to use those artifacts in the GCS emulator.
# File layout of the preloaded GCS data
dev/local_setup
└── gcs
└── merino-images-prodpy <- GCS Bucket ID
└── top_picks_latest.json <- A preloaded GCS blob
Note that any contents in dev/local_setup/gcs will not be checked into the source control nor the
docker image of Merino. (There are exceptions to this, e.g. logos necessary for tests. These
exceptions are managed in the root .gitignore file.)
Dev Helpers
The docker-compose setup also includes some services that can help during development.
- Redis Commander, http://localhost:8081 - Explore the Redis database started above.
Logging and Metrics
To get data out of Merino and into observable systems, we use metrics and logging. Each has a unique use case. Note that in general, because of the scale we work at, adding a metric or log event in production is not free, and if we are careless can end up costing quite a bit. Record what is needed, but don't go over board.
All data collection that happens in production (logging at INFO, WARN, or ERROR
levels; and metrics) should be documented in docs/data.md.
Logging
Merino uses MozLog for structured logging. Logs can be recorded through the
standard Python logging module. Merino can output logs in various formats,
including a JSON format (MozLog) for production. A pretty, human readable format
is also provided for development and other use cases.
Types
MozLog requires that all messages have a type value. By convention, we use
the name of the Python module, where the log record get issued, to populate this
field. For example:
import logging
logger = logging.getLogger(__name__)
# The `type` field of the log record will be the same as `__name__`.
logger.info("A new log message", data=extra_fields)
In general, the log message ("An empty MultiProvider was created") and the log type should both tell the reader what has happened. The difference is that the message is for humans and the type is for machines.
Levels
Tracing provides five log levels that should be familiar. This is what we mean by them in Merino:
-
CRITICAL- There was a serious error indicating that the program itself may be unable to continue running. -
ERROR- There was a problem, and the task was not completable. This usually results in a 500 being sent to the user. All error logs encountered in production are reported to Sentry and should be considered a bug. If it isn't a bug, it shouldn't be logged as an error. -
WARNING- There was a problem, but the task was able to recover. This doesn't usually affect what the user sees. Warnings are suitable for unexpected but "in-spec" issues, like a sync job not returning an empty set or using a deprecated function. These are not reported to Sentry. -
INFO- This is the default level of the production service. Use for logging that something happened that isn't a problem and we care about in production. This is the level that Merino uses for it's one-per-request logs and sync status messages. Be careful adding new per-request logs at this level, as they can be expensive. -
DEBUG- This is the default level for developers running code locally. Use this to give insight into how the system is working, but keep in mind that this will be on by default, so don't be too noisy. Generally this should summarize what's happening, but not give the small details like a log line for every iteration of a loop. Since this is off in production, there are no cost concerns.
Metrics
Merino metrics are reported as Statsd metrics.
Unlike logging, the primary way that metrics reporting can cost a lot is in cardinality. The number of metric IDs we have and the combination of tag values that we supply. Often the number of individual events doesn't matter as much, since multiple events are aggregated together.
Middlwares
Merino leverages middleware for various functionalities such as logging, metrics,
parsing for geolocation & user agent, feature flags etc. Middleware is defined
in the merino/middleware directory.
Caveat
We currently don't implement middleware using the middleware facilities provided by FastAPI/Starlette as they've shown significant performance overhead, preventing Merino from achieving the SLOs required by Firefox Suggest.
Before those performance issues get resolved in the upstream, we will be implementing
middleware for Merino through the ASGI protocol. You can also reference this
tutorial to learn more about ASGI. See Starlette's middleware document
for more details about how to write pure ASGI middlewares. Specifically, we can reuse
Starlette's data structures (Request, Headers, QueryParams etc.) to facilitate
the implementation.
Feature Flags
Usage
Do you plan to release code behind a feature flag? Great! 😃
Your feature flag needs to be defined first. If it's already defined, go ahead. Otherwise check the configuration section below before you continue.
Use the following line in API endpoint code to gain access to the feature flags object:
feature_flags: FeatureFlags = request.scope[ScopeKey.FEATURE_FLAGS]
Then check whether a certain feature flag, such as example, is enabled by calling:
if feature_flags.is_enabled("example"):
print("feature flag 'example' is enabled! 🚀")
When you do that, the decision (whether the feature flag is enabled or not) is
recorded and stored in a dict on the decisions attribute of the feature
flags object.
Implementation
The feature flags system in Merino consists of three components:
| Description | Location |
|---|---|
A FastAPI middleware that reads the query parameter sid sent by the client application and sets a session ID for the current request based on that. | merino/middleware/featureflags.py |
A FeatureFlags class which you can use to check if a certain feature flag is enabled. | merino/featureflags.py |
| A local directory containing static files that define and configure feature flags for Merino. | merino/configs/flags/ |
Configuration
Currently two bucketing schemes are supported: random and session.
Random
Random does what it says on the tin. It generates a random bucketing ID for every flag check.
Session
Session bucketing uses the session ID of the request as the bucketing key so that feature checks within a given search session would be consistent.
Fields
Each flag defines the following fields:
[default.flags.<flag_name>]
scheme = 'session'
enabled = 0.5
| Field | Description |
|---|---|
scheme | This is the bucketing scheme for the flag. Allowed values are 'random' and 'session' |
enabled | This represents the % enabled for the flag and must be a float between 0 and 1 |
Metrics
When submitting application metrics, feature flag decisions that were made while processing the current request up to this point are automatically added as tags to the emitted metrics.
The format of these tags is:
feature_flag.<feature_flag_name>
For more information about this see the ClientMeta meta class and the
add_feature_flags decorator in merino/metrics.py.
Monitoring in Grafana
Because feature flag decisions are automatically added as tags to emitted metrics, you can use them in your queries in Grafana. 📈
For example, if you want to group by decisions for a feature flag with name
hello_world, you can use tag(feature_flag.hello_world) in GROUP BY in
Grafana. You can also use [[tag_feature_flag.hello_world]] in the ALIAS for
panel legends.
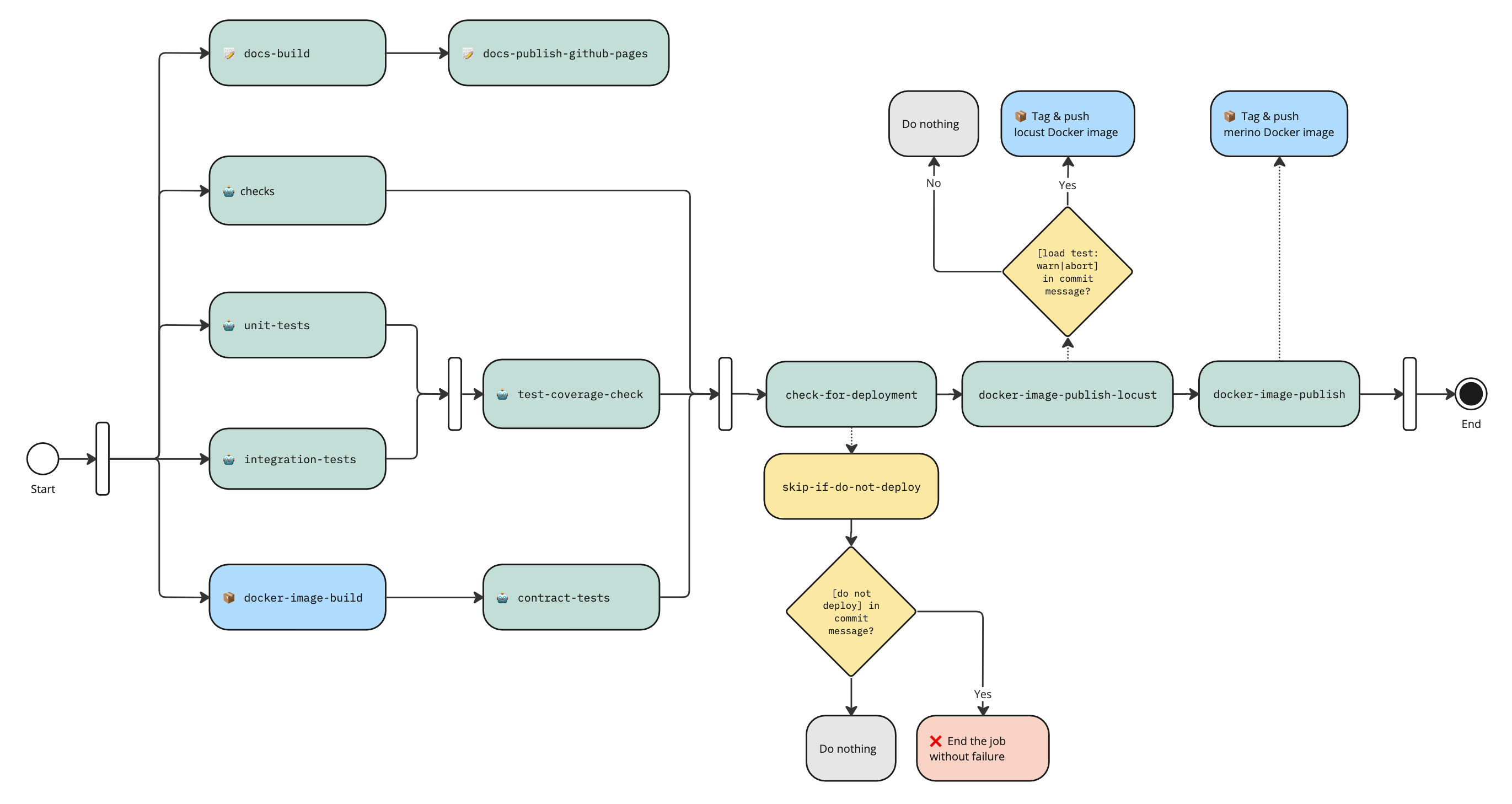
The Release Process
This project currently follows a Continuous Deployment process.
Whenever a commit is pushed to this repository's main branch, a CircleCI workflow is triggered
which performs code checks and runs automated tests. The workflow additionally builds a new Docker
image of the service and pushes that Docker image to the Docker Hub registry (this requires all
previous jobs to pass).
Pushing a new Docker image to the Docker Hub registry triggers a webhook that starts the Jenkins
deployment pipeline (the Docker image tag determines the target environment). The deployment
pipeline first deploys to the stage environment and subsequently to the
production environment.
After the deployment is complete, accessing the __version__ endpoint will show
the commit hash of the deployed version, which will eventually match to the one of the latest commit
on the main branch (a node with an older version might still serve the request before it is shut
down).
Release Best Practices
The expectation is that the author of the change will:
- merge pull requests during hours when the majority of contributors are online
- monitor the [Merino Application & Infrastructure][merino_app_info] dashboard for any anomaly
Versioning
The commit hash of the deployed code is considered its version identifier. The commit hash can be
retrieved locally via git rev-parse HEAD.
Load Testing
Load testing can be performed either locally or during the deployment process. During deployment, load tests are run against the staging environment before Merino-py is promoted to production.
Load tests in continuous deployment are controlled by adding a specific label to the commit message
being deployed. The format for the label is [load test: (abort|skip|warn)]. Typically, this label
is added to the merge commit created when a GitHub pull request is integrated.
abort: Stops the deployment if the load test fails.skip: Skips load testing entirely during deployment.warn: Proceeds with the deployment even if the load test fails, but sends a warning notification through Slack.
If no label is included in the commit message, the default behavior is to run the load test and issue a warning if it fails.
For more detailed information about load testing procedures and conventions, please refer to the Load Test README.
Logs from load tests executed in continuous deployment are available in the /data volume of the
Locust master kubernetes pod.
What to do if production breaks?
If your latest release causes problems and needs to be rolled back: don't panic and follow the instructions in the Rollback Runbook.
What to do if tests fail during deployment?
Please refer to What to do with Test Failures in CI?
Profiling
As Merino runs as a single-threaded application using the asyncio-based framework, it would be useful for engineers to get a good understanding about how Merino performs and where it spends time and memory doing what tasks to serve the requests. Local profiling offers us a way to look into those low-level details.
We use Scalene as the profiler to conduct the profiling for Merino. It's very easy to use, offers extremely detailed (at the line level) insights with much lower overhead compared to other profilers.
Usage
To start the profiling, you can run the following to start Merino with Scalene:
$ make profile
# or you can run it directly
$ python -m scalene merino/main.py
Then you can send requests to Merino manually or through using other load testing tools. Once that's done, you can terminate the Merino application. It will automatically collect profiling outputs (CPU & Memory) and open it in your browser.
Understand the outputs
Out of the box, Scalene provides a very intuitive web interface to display the profiling outputs. It's organized at the file (module) level. For each file, it shows the CPU time and average memory usage for both the line profile and the function profile of that module. You can also click on specific columns to sort the lines or functions accordingly.
For more details of how to read the outputs, you can reference Scalene's documents.
Equipped with those insights, you can have a good understanding about the application, identify hotspots, bottlenecks, or other findings that are not easy to uncover by only reading the source code. And then, you can tweak or fix those issues, test or profile it again to verify if the fix is working.
Merino Testing
Test Strategy
Merino is tested using a combination of functional and performance tests.
Test code resides in the tests directory.
Merino's test strategy requires that we do not go below a minimum test coverage percentage for unit and integration tests. Load tests cannot go below a minimum performance threshold.
Functional tests push test artifacts, in the form of JUnit XMLs and Coverage JSONs to the ETE Test Metric Pipeline for trending and monitoring. Results can be found on the Merino-py Test Metrics Looker Dashboard.
Test documentation resides in the /docs/testing/ directory.
The test strategy is three-tiered, composed of:
See documentation and repositories in each given test area for specific details on running and maintaining tests.
Unit Tests
The unit layer is suitable for testing complex behavior at a small scale, with fine-grained control over the inputs. Due to their narrow scope, unit tests are fundamental to thorough test coverage.
To execute unit tests, use: make unit-tests
Unit tests are written and executed with pytest and are located in the tests/unit directory,
using the same organizational structure as the source code of the merino service.
Type aliases dedicated for test should be stored in the types.py module.
The conftest.py modules contain common utilities in fixtures.
For a breakdown of fixtures in use per test, use: make unit-test-fixtures
Fixtures
Available fixtures include:
FilterCaplogFixture
Useful when verifying log messages, this fixture filters log records captured with
pytest's caplog by a given logger_name.
Usage:
def test_with_filter_caplog(
caplog: LogCaptureFixture, filter_caplog: FilterCaplogFixture
) -> None:
records: list[LogRecord] = filter_caplog(caplog.records, "merino.providers.suggest.adm")
Note: This fixture is shared with integration tests.
SuggestionRequestFixture
For use when querying providers, this fixture creates a SuggestionRequest object with
a given query
Usage:
def test_with_suggestion_request(srequest: SuggestionRequestFixture) -> None:
request: SuggestionRequest = srequest("example")
result: list[BaseSuggestion] = await provider.query(request)
ScopeFixture, ReceiveMockFixture & SendMockFixture
For use when testing middleware, these fixtures initialize or mock the common Scope, Receive and Send object dependencies.
Usage:
def test_middleware(scope: Scope, receive_mock: Receive, send_mock: Send) -> None:
pass
Integration Tests
The integration layer of testing allows for verification of interactions between service components, with lower development, maintenance and execution costs compared with higher level tests.
To execute integration tests, make sure you have Docker installed and a docker daemon running. Then use: make integration-tests
Integration tests are located in the tests/integration directory.
They use pytest and the FastAPI TestClient to send requests to specific merino endpoints and verify responses as well as other outputs, such as logs.
Tests are organized according to the API path under test.
Type aliases dedicated for test should be stored in the types.py module.
Fake providers created for test should be stored in the fake_providers.py module.
The conftest.py modules contain common utilities in fixtures.
We have also added integration tests that use Docker via the testcontainers library. See fixture example below.
For a breakdown of fixtures in use per test, use: make integration-test-fixtures
Fixtures
Available fixtures include:
FilterCaplogFixture
Details available in Unit Tests section
TestClientFixture
This fixture creates an instance of the TestClient to be used in testing API calls.
Usage:
def test_with_test_client(client: TestClient):
response: Response = client.get("/api/v1/endpoint")
TestClientWithEventsFixture
This fixture creates an instance of the TestClient, that will trigger event handlers
(i.e. startup and shutdown) to be used in testing API calls.
Usage:
def test_with_test_client_with_event(client_with_events: TestClient):
response: Response = client_with_events.get("/api/v1/endpoint")
InjectProvidersFixture & ProvidersFixture
These fixture will setup and teardown given providers.
Usage:
If specifying providers for a module:
@pytest.fixture(name="providers")
def fixture_providers() -> Providers:
return {"test-provider": TestProvider()}
If specifying providers for a test:
@pytest.mark.parametrize("providers", [{"test-provider": TestProvider()}])
def test_with_provider() -> None:
pass
SetupProvidersFixture
This fixture sets application provider dependency overrides.
Usage:
def test_with_setup_providers(setup_providers: SetupProvidersFixture):
providers: dict[str, BaseProvider] = {"test-provider": TestProvider()}
setup_providers(providers)
TeardownProvidersFixture
This fixture resets application provider dependency overrides and is often used in teardown fixtures.
Usage:
@pytest.fixture(autouse=True)
def teardown(teardown_providers: TeardownProvidersFixture):
yield
teardown_providers()
TestcontainersFixture
See tests/integration/jobs/navigational_suggestions/test_domain_metadata_uploader.py for a detailed example.
This is a lightweight example on how to set up a docker container for your integration tests.
Usage:
@pytest.fixture(scope="module")
def your_docker_container() -> DockerContainer:
os.environ.setdefault("STORAGE_EMULATOR_HOST", "http://localhost:4443")
container = (
DockerContainer("your-docker-image")
.with_command("-scheme http")
.with_bind_ports(4443, 4443)
).start()
# wait for the container to start and emit logs
delay = wait_for_logs(container, "server started at")
port = container.get_exposed_port(4443)
yield container
container.stop()
Merino Load (Locust) Tests
This documentation describes the load tests for Merino. This test framework uses IP2Location LITE data available from https://lite.ip2location.com
Overview
The tests in the tests/load directory spawn multiple HTTP clients that consume Merino's API,
in order to simulate real-world load on the Merino infrastructure.
These tests use the Locust framework and are triggered at the discretion of the Merino Engineering Team.
Related Documentation
Local Execution
Note that if you make changes to the load test code, you must stop and remove the Docker containers and networks for changes to reflect.
Do this by running make load-tests-clean.
Follow the steps bellow to execute the load tests locally:
Setup Environment
1. Configure Environment Variables
The following environment variables as well as
Locust environment variables can be set in
tests\load\docker-compose.yml.
Make sure any required API key is added but then not checked into source control.
WARNING: if the WIKIPEDIA__ES_API_KEY is missing, the MerinoUser load tests will
not execute. WcsUser runs do not require the Suggest bootstrap variables.
| Environment Variable | Node(s) | Description |
|---|---|---|
| LOAD_TESTS__LOGGING_LEVEL | master & worker | Level for the logger in the load tests as an int (10 for DEBUG, 20 for INFO etc.) |
| LOAD_TESTS__WCS__HOST | master & worker | Default host for WCS-only load tests. Defaults to https://merino.services.allizom.org |
| LOAD_TESTS__WCS__DESKTOP_WEIGHT | master & worker | Relative weight for Firefox desktop User-Agent headers in WCS requests. Defaults to 1 |
| LOAD_TESTS__WCS__MOBILE_WEIGHT | master & worker | Relative weight for Firefox mobile User-Agent headers in WCS requests. Defaults to 1 |
| LOAD_TESTS__WCS__DATES | master & worker | Optional comma-separated WCS match dates. Defaults to local WCS schedule data |
| LOAD_TESTS__WCS__TEAM_KEYS | master & worker | Optional comma-separated WCS team keys. Defaults to local WCS team data |
| MERINO_REMOTE_SETTINGS__SERVER | master & worker | Server URL of the Kinto instance containing suggestions |
| MERINO_REMOTE_SETTINGS__BUCKET | master & worker | Kinto bucket with the suggestions |
| MERINO_REMOTE_SETTINGS__COLLECTION | master & worker | Kinto collection with the suggestions |
| MERINO_PROVIDERS__TOP_PICKS__TOP_PICKS_FILE_PATH | master & worker | The minimum character limit set for long domain suggestion indexing |
| MERINO_PROVIDERS__TOP_PICKS__QUERY_CHAR_LIMIT | master & worker | The minimum character limit set for short domain suggestion indexing |
| MERINO_PROVIDERS__TOP_PICKS__FIREFOX_CHAR_LIMIT | master & worker | File path to the json file of domains |
| MERINO_PROVIDERS__WIKIPEDIA__ES_API_KEY | master & worker | The base64 key used to authenticate on the Elasticsearch cluster specified by es_cloud_id |
| MERINO_PROVIDERS__WIKIPEDIA__ES_URL | master & worker | The Cloud ID of the Elasticsearch cluster |
| MERINO_PROVIDERS__WIKIPEDIA__ES_INDEX | master & worker | The index identifier of Wikipedia in Elasticsearch |
2. Host Locust via Docker
Execute the following from the repository root:
make load-tests
3. (Optional) Host Merino Locally
Use one of the following commands to host Merino locally. Execute the following from the repository root:
- Option 1: Use the local development instance
make dev - Option 2: Use the profiler instance
make profile - Option 3: Use the Docker instance
make docker-build && docker run -p 8000:8000 app:build
Run Test Session
1. Start Load Test
- In a browser navigate to
http://localhost:8089/ - Set up the load test parameters:
- Option 1: Select the
MerinoSmokeLoadTestShapeorMerinoAverageLoadTestShape- These options have pre-defined settings
- Option 2: Select the
Defaultload test shape with the following recommended settings:- Number of users: 25
- Spawn rate: 1
- Host: 'https://merino.services.allizom.org'
- Set host to 'http://host.docker.internal:8000' to test against a local instance of Merino
- Duration (Optional): 10m
- Option 1: Select the
- Select "Start Swarming"
2. Stop Load Test
Select the 'Stop' button in the top right hand corner of the Locust UI, after the desired test duration has elapsed. If the 'Run time' is set in step 1, the load test will stop automatically.
3. Analyse Results
- See Distributed GCP Execution (Manual Trigger) - Analyse Results
- Only client-side measures, provided by Locust, are available when executing against a local instance of Merino.
Clean-up Environment
1. Remove Load Test Docker Containers
Execute the following from the repository root:
make load-tests-clean
Distributed GCP Execution - Manual Trigger
Follow the steps bellow to execute the distributed load tests on GCP with a manual trigger:
Setup Environment
1. Start a GCP Cloud Shell
The load tests can be executed from the contextual-services-test-eng cloud shell.
2. Configure the Bash Script
- The
setup_k8s.shfile, located in thetests\loaddirectory, contains shell commands to create a GKE cluster, setup an existing GKE cluster or delete a GKE cluster- Modify the script to include the MERINO_PROVIDERS__WIKIPEDIA__ES_API_KEY environment variables
- Execute the following from the root directory, to make the file executable:
chmod +x tests/load/setup_k8s.sh
3. Create the GCP Cluster
- Execute the
setup_k8s.shfile and select the create option, in order to initiate the process of creating a cluster, setting up the env variables and building the docker image. Choose smoke or average depending on the type of load test required../tests/load/setup_k8s.sh create [smoke|average]- Smoke - The smoke load test verifies the system's performance under minimal load. The test is run for a short period, possibly in CD, to ensure the system is working correctly.
- Average - The average load test measures the system's performance under standard operational conditions. The test is meant to reflect an ordinary day in production.
- The cluster creation process will take some time. It is considered complete, once
an external IP is assigned to the
locust_masternode. Monitor the assignment via a watch loop:kubectl get svc locust-master --watch - The number of workers is defaulted to 5, but can be modified with the
kubectl scalecommand. Example (10 workers):kubectl scale deployment/locust-worker --replicas=10 - To apply new changes to an existing GCP Cluster, execute the
setup_k8s.shfile and select the setup option.- This option will consider the local commit history, creating new containers and deploying them (see Artifact Registry)
Run Test Session
1. Start Load Test
-
In a browser navigate to
http://$EXTERNAL_IP:8089This url can be generated via command
EXTERNAL_IP=$(kubectl get svc locust-master -o jsonpath="{.status.loadBalancer.ingress[0].ip}") echo http://$EXTERNAL_IP:8089 -
Select the
MerinoSmokeLoadTestShape, this option has pre-defined settings and will last 5 minutes -
Select "Start Swarming"
2. Stop Load Test
Select the 'Stop' button in the top right hand corner of the Locust UI, after the desired test duration has elapsed. If the 'Run time' is set in step 1, the load test will stop automatically.
3. Analyse Results
RPS
- The request-per-second load target for Merino is
1500 - Locust reports client-side RPS via the "merino_stats.csv" file and the UI (under the "Statistics" tab or the "Charts" tab)
- Grafana reports the server-side RPS via the "HTTP requests per second per country" chart
HTTP Request Failures
- The number of responses with errors (5xx response codes) should be
0 - Locust reports Failures via the "merino_failures.csv" file and the UI (under the "Failures" tab or the "Charts" tab)
- Grafana reports Failures via the "HTTP Response codes" chart and the "HTTP 5xx error rate" chart
Exceptions
- The number of exceptions raised by the test framework should be
0 - Locust reports Exceptions via the "merino_exceptions.csv" file and the UI (under the "Exceptions" tab)
Latency
- The HTTP client-side response time (aka request duration) for 95 percent of users
is required to be 200ms or less (
p95 <= 200ms), excluding weather requests - Locust reports client-side latency via the "merino_stats.csv" file and the UI
(under the "Statistics" tab or the "Charts" tab)
- Warning! A Locust worker with too many users will bottleneck RPS and inflate client-side latency measures. Locust reports worker CPU and memory usage metrics via the UI (under the "Workers" tab)
- Grafana reports server-side latency via the "p95 latency" chart
Resource Consumption
- To conserve costs, resource allocation must be kept to a minimum. It is expected that container, CPU and memory usage should trend consistently between load test runs.
- Grafana reports metrics on resources via the "Container Count", "CPU usage time sum" and "Memory usage sum" charts
4. Report Results
- Results should be recorded in the Merino Load Test Spreadsheet
- Optionally, the Locust reports can be saved and linked in the spreadsheet:
- Download the results via the Locust UI or via command:
Thekubectl cp <master-pod-name>:/home/locust/merino_stats.csv merino_stats.csv kubectl cp <master-pod-name>:/home/locust/merino_exceptions.csv merino_exceptions.csv kubectl cp <master-pod-name>:/home/locust/merino_failures.csv merino_failures.csvmaster-pod-namecan be found at the top of the pod list:kubectl get pods -o wide - Upload the files to the ConServ drive and record the links in the spreadsheet
- Download the results via the Locust UI or via command:
Clean-up Environment
1. Delete the GCP Cluster
Execute the setup_k8s.sh file and select the delete option
./tests/load/setup_k8s.sh
Distributed GCP Execution - CI Trigger
The load tests are triggered in CI via Jenkins, which has a command overriding the load test Dockerfile entrypoint.
Follow the steps below to execute the distributed load tests on GCP with a CI trigger:
Run Test Session
1. Execute Load Test
To modify the load testing behavior, you must include a label in your Git commit. This must be the
merge commit on the main branch, since only the most recent commit is checked for the label. The
label format is: [load test: (abort|skip|warn)]. Take careful note of correct syntax and spacing
within the label. There are three options for load tests: abort, skip, and warn:
- The
abortlabel will prevent a prod deployment if the load test fails
Ex.feat: Add feature ABC [load test: abort]. - The
skiplabel will bypass load testing entirely during deployment
Ex.feat: Add feature LMN [load test: skip]. - The
warnlabel will output a Slack warning if the load test fails but still allow for the production deployment
Ex.feat: Add feature XYZ [load test: warn].
If no label is included in the commit message, the load test will be executed with the warn
action.
The commit tag signals load test instructions to Jenkins by modifying the Docker image tag. The
Jenkins deployment workflow first deploys to stage and then runs load tests if requested. The
Docker image tag passed to Jenkins appears as follows:
^(?P<environment>stage|prod)(?:-(?P<task>\w+)-(?P<action>abort|skip|warn))?-(?P<commit>[a-z0-9]+)$
2. Analyse Results
See Distributed GCP Execution (Manual Trigger) - Analyse Results
3. Report Results
- Optionally, results can be recorded in the Merino Load Test Spreadsheet. It is recommended to do so if unusual behavior is observed during load test execution or if the load tests fail.
- The Locust reports can be saved and linked in the spreadsheet. The results are persisted in the
/datadirectory of thelocust-master-0pod in thelocust-masterk8s cluster in the GCP project ofmerino-nonprod. To access the Locust logs:- Open a cloud shell in the Merino stage environment
- Authenticate by executing the following command:
gcloud container clusters get-credentials merino-nonprod-v1 \ --region us-west1 --project moz-fx-merino-nonprod-ee93 - Identify the log files needed in the Kubernetes pod by executing the following command, which
lists the log files along with file creation timestamp when the test was performed. The
{run-id}uniquely identifies each load test run:kubectl exec -n locust-merino locust-master-0 -- ls -al /data/ - Download the results via the Locust UI or via command:
kubectl -n locust-merino cp locust-master-0:/data/{run-id}-merino_stats.csv merino_stats.csv kubectl -n locust-merino cp locust-master-0:/data/{run-id}-merino_exceptions.csv merino_exceptions.csv kubectl -n locust-merino cp locust-master-0:/data/{run-id}-merino_failures.csv merino_failures.csv - Upload the files to the ConServ drive and record the links in the spreadsheet
Calibration
Following the addition of new features, such as a Locust Task or Locust User, or environmental changes, such as node size or the upgrade of a major dependency like the python version image, it may be necessary to re-establish the recommended parameters of the performance test.
| Parameter | Description |
|---|---|
WAIT TIME | - Changing this cadence will increase or decrease the number of channel subscriptions and notifications sent by a MerinoUser. - The default is currently in use for the MerinoUser class. |
TASK WEIGHT | - Changing this weight impacts the probability of a task being chosen for execution. - This value is hardcoded in the task decorators of the MerinoUser class. |
USERS_PER_WORKER | - This value should be set to the maximum number of users a Locust worker can support given CPU and memory constraints. - This value is hardcoded in the LoadTestShape classes. |
WORKER_COUNT | - This value is derived by dividing the total number of users needed for the performance test by the USERS_PER_WORKER. - This value is hardcoded in the LoadTestShape classes and the setup_k8s.sh script. |
- Locust documentation is available for [WAIT TIME][13] and [TASK WEIGHT][14]
Calibrating for USERS_PER_WORKER
This process is used to determine the number of users that a Locust worker can support.
Setup Environment
1. Start a GCP Cloud Shell
The load tests can be executed from the contextual-services-test-eng cloud shell. If executing a load test for the first time, the git merino-py repository will need to be cloned locally.
2. Configure the Bash Script
- The
setup_k8s.shfile, located in thetests\loaddirectory, contains shell commands to create a GKE cluster, setup an existing GKE cluster or delete a GKE cluster- Execute the following from the root directory, to make the file executable:
chmod +x tests/load/setup_k8s.sh
- Execute the following from the root directory, to make the file executable:
3. Create the GCP Cluster
- In the
setup_k8s.shscript, modify theWORKER_COUNTvariable to equal1 - Execute the
setup_k8s.shfile from the root directory and select the create option, in order to initiate the process of creating a cluster, setting up the env variables and building the docker image. Choose smoke or average depending on the type of load test required../tests/load/setup_k8s.sh create [smoke|average] - The cluster creation process will take some time. It is considered complete, once
an external IP is assigned to the
locust_masternode. Monitor the assignment via a watch loop:kubectl get svc locust-master --watch
Calibrate
Repeat steps 1 to 3, using a process of elimination, such as the bisection method, to
determine the maximum USERS_PER_WORKER. The load tests are considered optimized when
CPU and memory resources are maximally utilized. This step is meant to determine the
maximum user count that a node can accommodate by observing CPU and memory usage while
steadily increasing or decreasing the user count. You can monitor the CPU percentage in
the Locust UI but also in the Kubernetes engine Workloads tab where both memory and CPU
are visualized on charts.
1. Start Load Test
- In a browser navigate to
http://$EXTERNAL_IP:8089This url can be generated via commandEXTERNAL_IP=$(kubectl get svc locust-master -o jsonpath="{.status.loadBalancer.ingress[0].ip}") echo http://$EXTERNAL_IP:8089 - Set up the load test parameters:
- ShapeClass: Default
- UserClasses: MerinoUser
- Number of users: USERS_PER_WORKER (Consult the Merino_spreadsheet to determine a starting point)
- Ramp up: RAMP_UP (RAMP_UP = 5/USERS_PER_WORKER)
- Host: 'https://merino.services.allizom.org'
- Duration (Optional): 600s
- Select "Start Swarm"
2. Stop Load Test
Select the 'Stop' button in the top right hand corner of the Locust UI, after the desired test duration has elapsed. If the 'Run time' or 'Duration' is set in step 1, the load test will stop automatically.
3. Analyse Results
CPU and Memory Resource Graphs
- CPU and Memory usage should be less than 90% of the available capacity
- CPU and Memory Resources can be observed in Google Cloud > Kubernetes Engine > Workloads
Log Errors or Warnings
- Locust will emit errors or warnings if high CPU or memory usage occurs during the
execution of a load test. The presence of these logs is a strong indication that the
USERS_PER_WORKERcount is too high
4. Report Results
See Distributed GCP Execution (Manual Trigger) - Analyse Results
5. Update Shape and Script Values
WORKER_COUNT = MAX_USERS/USERS_PER_WORKER- If
MAX_USERSis unknown, calibrate to determineWORKER_COUNT
- If
- Update the
USERS_PER_WORKERandWORKER_COUNTvalues in the following files:\tests\load\locustfiles\smoke_load.pyor\tests\load\locustfiles\average_load.py- \tests\load\setup_k8s.sh
Clean-up Environment
See Distributed GCP Execution (Manual Trigger) - Clean-up Environment
Calibrating for WORKER_COUNT
This process is used to determine the number of Locust workers required in order to generate sufficient load for a test given a SHAPE_CLASS.
Setup Environment
- See Distributed GCP Execution (Manual Trigger) - Setup Environment
- Note that in the
setup_k8s.shthe maximum number of nodes is set using thetotal-max-nodesgoogle cloud option. It may need to be increased if the number of workers can't be supported by the cluster.
Calibrate
Repeat steps 1 to 4, using a process of elimination, such as the bisection method, to
determine the maximum WORKER_COUNT. The tests are considered optimized when they
generate the minimum load required to cause node scaling in the the Merino-py Stage
environment. You can monitor the Merino-py pod counts on Grafana.
1. Update Shape and Script Values
- Update the
WORKER_COUNTvalues in the following files:\tests\load\locustfiles\smoke_load.pyor\tests\load\locustfiles\average_load.py- \tests\load\setup_k8s.sh
- Using Git, commit the changes locally
2. Start Load Test
- In a browser navigate to
http://$EXTERNAL_IP:8089This url can be generated via commandEXTERNAL_IP=$(kubectl get svc locust-master -o jsonpath="{.status.loadBalancer.ingress[0].ip}") echo http://$EXTERNAL_IP:8089 - Set up the load test parameters:
- ShapeClass: SHAPE_CLASS
- Host: 'https://merino.services.allizom.org'
- Select "Start Swarm"
3. Stop Load Test
Select the 'Stop' button in the top right hand corner of the Locust UI, after the desired test duration has elapsed. If the 'Run time', 'Duration' or 'ShapeClass' are set in step 1, the load test will stop automatically.
4. Analyse Results
Stage Environment Pod Counts
- The 'Merino-py Pod Count' should demonstrate scaling during the execution of the load test
- The pod counts can be observed in Grafana
CPU and Memory Resources
- CPU and Memory usage should be less than 90% of the available capacity in the cluster
- CPU and Memory Resources can be observed in Google Cloud > Kubernetes Engine > Workloads
5. Report Results
Clean-up Environment
Maintenance
The load test maintenance schedule cadence is once a quarter and should include updating the following:
- uv version and python dependencies
- Docker artifacts
- Distributed GCP execution scripts and Kubernetes configurations
- Documentation
Providers
Providers return suggestions for queries. By default, each query to the /suggest endpoint is dispatched asynchronously to every enabled provider. The providers query param can be used to specify which providers should serve the request. The provider determines whether the query is relevant to its domain and responds appropriately.
The /providers endpoint provides a list of available providers. See the API docs for more information.
Provider documentation:
- Flights
- Finance (stocks)
- Sports
- Weather
- ADM (sponsored content)
- AMO (Addons)
- Wikipedia
- Top Picks
Flight Status Provider
Handles flight status queries from the Firefox address bar. If the sanitized query matches a flight number in a GCS-sourced manifest, respond with flight details from a Redis cache, or live AeroAPI (FlightAware) calls on cache miss. This provider is fronted by a circuit breaker.
Request Flow
sequenceDiagram
actor Firefox
participant Merino
participant GCS
participant Redis
participant AeroAPI as AeroAPI (FlightAware)
Firefox->>Merino: GET /api/v1/suggest?q=ac 100
alt Flight number not in manifest
Merino-->>Firefox: { suggestions: [] }
else Flight number in manifest
Merino->>Redis: Look up flight status
alt Cached
Redis-->>Merino: Flight data
else Not cached
Redis-->>Merino: (miss)
Merino->>AeroAPI: GET /flights/AC100
AeroAPI-->>Merino: Flight data
Merino->>Redis: Store flight data
end
Merino-->>Firefox: { suggestions: [{provider: "flightaware", ...}] }
end
Flight Numbers Manifest Sync
Flight numbers are loaded into memory from GCS on app startup and refreshed periodically (see config). This is an append-only manifest which contains all flight numbers that have been synced via the scheduled flight numbers ingestion job.
sequenceDiagram
participant Merino
participant GCS
Note over Merino: App startup
Merino->>GCS: Fetch flight number manifest
GCS-->>Merino: list of valid flight numbers
Note over Merino: Stores manifest in memory
loop Periodic refresh
Merino->>GCS: Fetch flight number manifest
GCS-->>Merino: list of valid flight numbers
Note over Merino: Updates in-memory manifest
end
Flight Numbers Ingestion Job (Manifest update)
This ingest job fetches flight numbers for scheduled flights from AeroAPI every 6 hours, and adds them to the existing flight numbers manifest(s) in GCS. Currently two copies of the manifests are stored in separate buckets as part of ongoing GCP v2 migration.
The job scheduling and invocation is handled by Airflow (see dags here).
sequenceDiagram
participant Job as fetch_flights Job
participant AeroAPI as AeroAPI (FlightAware)
participant GCS
loop Every 6 hours
Job->>AeroAPI: GET scheduled flights
AeroAPI-->>Job: Page of scheduled flights
end
Job->>GCS: Download existing flight_numbers_latest.json
GCS-->>Job: Existing flight number list
Note over Job: Merge new + existing (union)
Job->>GCS: Upload flight_numbers_latest.json (×2 buckets)
Note that the job can be configured to store the manifest in Redis by setting settings.flightaware.storage (resolves to MERINO_FLIGHTAWARE__STORAGE env var) to redis. However, the provider is only configured to fetch the manifest from GCS.
Operations
This is where we put operational documentation for Merino.
How to Rollback Changes
Note: We use "roll-forward" strategy for rolling back changes in production.
- Depending on the severity of the problem, decide if this warrants kicking off an incident;
- Identify the problematic commit (it may not be the latest commit)
and create a revert PR.
If it is the latest commit, you can revert the change with:
git revert HEAD~1 - Create a revert PR and go through normal review process to merge PR.
Navigational Suggestions Job Blocklist
The Navigational Suggestions Job blocklist is contained in merino/utils/blocklists.py.
The TOP_PICKS_BLOCKLIST variable is used when running the indexing job and prevents the included domains from being added.
Add to Blocklist
- Go to
merino/utils/blocklists.py. - Add the second-level-domain to the
TOP_PICKS_BLOCKLISTset. - Open a PR and merge in the changes to block this domain from being indexed.
Remove from Blocklist
Repeat as above, just remove the domain from the TOP_PICKS_BLOCKLIST set.
- Note: removing from the blocklist means that the domain was likely not created during the Airflow job, so if you wish to see it re-added, supposing it is still in the top 1000 domains, you have to re-run the airflow job. See the instructions for this in the jobs/navigational_suggestions docs.
How to Add to the Wikipedia Indexer and Provider Blocklist
Provider - Rapid Blocklist Addition
These steps define how to rapidly add and therefore block a Wikipedia article by its title.
- In
/merino/utils/blocklists.py, add the matching title toTITLE_BLOCK_LIST.
NOTE: Ensure the title field is added as it appears with correct spacing between the words. In adding to the list, enter the title as it appears in Wikipedia. Membership checks of the block list are not case sensitive and any underscores in the titles should instead be spaces.
- Check in the changes to source control, merge a pull request with the new block list and deploy Merino.
Indexer Job
Since the indexer runs at a regular cadence, you do not need to re-run the Airflow job. Adding to the blocklist using the steps above is sufficient to rapidly block a title. The next time the Wikipedia indexer job runs, this title will be excluded during the indexer job.
NOTE: There are two blocklists referenced by the Wikipedia Indexer Job:
blocklist_file_url: a key contained in themerino/configs/default.tomlfile that points to a remote block list which encapsulates blocked categories.WIKIPEDIA_TITLE_BLOCKLIST: an application-level list of titles found at/merino/utils/blocklists.pyas explained above.
What to do with test failures in CI?
-
Investigate the cause of the test failure
- For unit or integration, logs can be found on CircleCI
- For performance tests (load), insights can be found on Grafana and in the Locust logs. To access the Locust logs see the Distributed GCP Exection - CI Trigger section of the load test documentation.
-
Fix or mitigate the failure
- If a fix can be identified in a relatively short time, then submit a fix
- If the failure is caused by a flaky or intermittent functional test and the risk to the
end-user experience is low, then the test can be "skipped", using the pytest
xfaildecorator during continued investigation. Example:@pytest.mark.xfail(reason="Test Flake Detected (ref: DISCO-####)")
-
Re-Deploy
- A fix or mitigation will most likely require a PR merge to the
mainbranch that will automatically trigger the deployment process. If this is not possible, a re-deployment can be initiated manually by triggering the CI pipeline in CircleCI.
- A fix or mitigation will most likely require a PR merge to the
Configuring Merino (Operations)
To manage configurations and view all documentation for individual config values, please view the default.toml file.
Settings
Merino's settings are managed via Dynaconf and can be specified in two ways:
- a TOML file in the
merino/configs/directory. - via environment variables.
Environment variables take precedence over the values set in the TOML files.
Production environment variables are managed by SRE and defined in the relevant merino-py repo.
TOML files set with the same environment name that is currently activated also automatically override defaults.
Any config file that is pointed to will override the
merino/configs/default.tomlfile.
File organization
These are the settings sources, with later sources overriding earlier ones.
-
A
config.pyfile establishes a Dynaconf instance and environment-specific values are pulled in from the corresponding TOML files and environment variables. Other configurations are established by files that are prefixed withconfig_*.py, such asconfig_sentry.pyorconfig_logging.py. -
Per-environment configuration files are in the
configsdirectory. The environment is selected using the environment variableMERINO_ENV. The settings for that environment are then loaded fromconfigs/${env}.toml, if the file/env exists. The default environment is "development". A "production" environment is also provided. -
Local configuration files are not checked into the repository, but if created should be named
configs/development.local.toml, following the format of<environment>.local.toml. This file is listed in the.gitignorefile and is safe to use for local configuration. One may add secrets here if desired, though it is advised to exercise great caution.
General
-
All environments are prefixed with
MERINO_. This is established in theconfig.pyfile by setting theenvvar_prefix="MERINO"for the Dynaconf instance. The first level followingMERINO_is accessed with a single underscore_and any subsequent levels require two underscores__. For example, the logging format can be controlled from the environment variableMERINO_LOGGING__FORMAT. -
Production environment variables are set by SRE and stored in the cloudops project in the
configmap.ymlfile. Contact SRE if you require information or access on this file, or request access to the cloudops infra repo. -
You can set these environment variables in your setup by modifying the
.tomlfiles. Conversely, when usingmake, you can prefixmake runwith overrides to the desired environment variables using CLI flags.Example:
MERINO_ENV=production MERINO_LOGGING__FORMAT=pretty make dev -
env(MERINO_ENV) - Only settable from environment variables. Controls which environment configuration is loaded, as described above. -
debug(MERINO_DEBUG) - Boolean that enables additional features to debug the application. This should not be set to true in public environments, as it reveals all configuration, including any configured secrets. -
format(MERINO_LOGGING__FORMAT) - Controls the format of outputted logs in eitherprettyormozlogformat. See config_logging.py.
Caveat
Be extra careful whenever you need to reference those deeply nested settings
(e.g. settings.foo.bar.baz) in the hot paths of the code base, such as middlewares
or route handlers. Under the hood, Dynaconf will perform a dictionary lookup
for each level of the configuration hierarchy. While it's harmless to do those
lookups once or twice, it comes a surprisingly high overhead if accessing them
repeatedly in the hot paths. You can cache those settings somewhere to mitigate
this issue.
Elasticsearch Operations
We use Elasticsearch as a source of data for one of our providers. This page documents some of the commands that we want to run on the cluster.
Elasticsearch Index Policy
We want to ensure that the index expire after 30 days, so we need to add a lifecycle policy for this deletion to happen.
The command to run in Kibana to add this policy:
PUT _ilm/policy/enwiki_policy
{
"policy": {
"phases": {
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
Closed Index Recovery
The indexing job currently closes the index after it migrates the alias to point to the new index. Closing the index removes the ability to query from the index but also reduces the heap memory usage when the index is not actively being queried.
If there is a situation where we need to recover a closed index to be the main index, we will need to do the following:
- Re-open the index
- Point the index alias to the recovered index
Jobs
Merino Jobs Operations
Navigational Suggestions
This document provides instructions and documentation on the navigational suggestions job.
This job creates a file that is ingested by the Top Picks/Navigational Suggestions provider.
The provider indexes a collection of the top 1000 searched domains and generates the top_picks.json file. Then the provider backend can serve suggestions that match query terms that are searched by the client to second-level domains.
If you need to run the navigational suggestions job ad-hoc, the quickest recommended solution is to run it in Airflow, download the top_picks.json file sent by email,
and then merge the new file into the Merino repo with the newly generated one.
If needing to update the blocklist to avoid certain domains and suggestions from being displayed, please see the navigational suggestions blocklist runbook.
Running the job in Airflow
Normally, the job is set as a cron to run at set intervals as a DAG in Airflow. There may be instances you need to manually re-run the job from the Airflow dashboard.
Grid View Tab (Airflow UI)
- Visit the Airflow dashboard for
merino_jobs. - In the Grid View Tab, select the task you want to re-run.
- Click on 'Clear Task' and the executor will re-run the job.

Graph View Tab (Airflow UI) - Alternative
- Visit the Airflow dashboard for
merino_jobs. - From the Graph View Tab, Click on the
nav_suggestions_prepare_domain_metadata_prodtask.
- Click on 'Clear' and the job will re-run.

At the conclusion of the job, you should recieve an email with a link to the newly generated file. Ensure you are a member of the disco-team email distro group to recieve the email.
Note: You can also re-run the stage job, but the changes won't reflect in production. Stage should be re-run in the event of an error before running in prod to verify the correction of an error.
See Airflow's documentation on re-running DAGs for more information and implementation details.
To see the code for the merino_jobs DAG, visit the telemetry-airflow repo. The source for the job is also in the 'code' tab in the airflow console.
To see the navigational suggestions code that is run when the job is invoked, visit Merino jobs/navigational_suggestions.
Running the favicon extractor locally
$ uv run probe-images mozilla.org wikipedia.org
There is a Python script (domain_tester.py) which imports the DomainProcessor, WebScraper and AsyncFaviconDownloader and runs them locally, without saving the results to the cloud.
This is meant to troubleshoot domains locally and iterate over the functionality in a contained environment.
Example output:
$ uv run probe-images mozilla.org wikipedia.org
Testing domain: mozilla.org
✅ Success!
Title Mozilla - Internet for people, not profit (UK)
Best Icon https://dummy-cdn.example.com/favicons/bd67680f7da3564bace91b2be87feab16d5e9e6266355b8f082e21f8159…
Total Favicons 4
All favicons found:
- https://www.mozilla.org/media/img/favicons/mozilla/apple-touch-icon.05aa000f6748.png (rel=apple-touch-icon
size=180x180 type=image/png)
- https://www.mozilla.org/media/img/favicons/mozilla/favicon-196x196.e143075360ea.png (rel=icon size=196x196
type=image/png)
- https://www.mozilla.org/media/img/favicons/mozilla/favicon.d0be64e474b1.ico (rel=shortcut,icon)
Testing domain: wikipedia.org
✅ Success!
Title Wikipedia
Best Icon https://dummy-cdn.example.com/favicons/4c8bf96d667fa2e9f072bdd8e9f25c8ba6ba2ad55df1af7d9ea0dd575c1…
Total Favicons 3
All favicons found:
- https://www.wikipedia.org/static/apple-touch/wikipedia.png (rel=apple-touch-icon)
- https://www.wikipedia.org/static/favicon/wikipedia.ico (rel=shortcut,icon)
Summary: 2/2 domains processed successfully
Adding new domains
- You can add new domains to the job by adding them to the
/merino/jobs/navigational_suggestions/custom_domains.pyfile. - Either manually, or you can use a script inside the
/scriptsfolder. - The script is called
import_domains.shand it works with a CSV file with aREGISTERED_DOMAINheader, and starting from the second row, the firsts column is the domain name (e.ggetpocket.com)
This step was introduced to give the HNT team an easy way of importing their updated domains.
Execute the script like this:
$ ./scripts/import_domains.sh DOWNLOADED_FILE.csv
This will add the domains to the custom_domains.py file, check if the domain exists, and if not, it adds it. Afterwards, all domains are getting alphabetically sorted.
Note
- Subdomains are supported and treated as distinct domains. For example,
sub.example.comis different fromexample.comand can be added separately.- Duplicate checks are done by exact domain string, not by apex/normalized form. If a custom domain exactly matches an existing domain, it will be skipped and logged as:
Skipped duplicate domains: <domain>.
Running the Navigational Suggestions job locally
The Navigational Suggestions job can be run locally for development and testing purposes without requiring access to Google Cloud. This is useful for testing changes to the favicon extraction and domain processing logic.
Prerequisites
- Docker installed and running
- Merino repository cloned locally
Running the job locally
There is one Make command which starts the Docker container for GCS, queries 20 domains, and stops the container afterwards.
$ make nav-suggestions
This will:
- Use a sample of domains from
custom_domains.pyinstead of querying BigQuery - Process these domains through the same extraction pipeline used in production
- Upload favicons and domain metadata to the local GCS emulator
- Generate a local metrics report in the
local_datadirectory
Examples
# With monitoring enabled
make nav-suggestions ENABLE_MONITORING=true
# With custom sample size
make nav-suggestions SAMPLE_SIZE=50
# With custom metrics directory
make nav-suggestions METRICS_DIR=./test_data
# With all options combined
make nav-suggestions SAMPLE_SIZE=30 METRICS_DIR=./test_data ENABLE_MONITORING=true
# Add any other options as needed
make nav-suggestions NAV_OPTS="--min-favicon-width=32"
Merino Jobs Operations
Dynamic Wikipedia Indexer Job
Merino currently builds the Elasticsearch indexing job that runs in Airflow.
Airflow takes the latest image built as the base image.
The reasons to keep the job code close to the application code are:
- Data models can be shared between the indexing job and application more easily. This means that data migrations will be simpler.
- All the logic regarding Merino functionality can be found in one place.
- Eliminates unintended differences in functionality due to dependency mismatch.
If your reason for re-running the job is needing to update the blocklist to avoid certain suggestions from being displayed, please see the wikipedia blocklist runbook.
Running the job in Airflow
Normally, the job is set as a cron to run at set intervals as a DAG in Airflow. There may be instances you need to manually re-run the job from the Airflow dashboard.
Grid View Tab (Airflow UI)
- Visit the Airflow dashboard for
merino_jobs. - In the Grid View Tab, select the task you want to re-run.
- Click on 'Clear Task' and the executor will re-run the job.

Graph View Tab (Airflow UI) - Alternative
- Visit the Airflow dashboard for
merino_jobs. - From the Graph View Tab, Click on the
wikipedia_indexer_build_index_productiontask.
- Click on 'Clear' and the job will re-run.

Note: You can also re-run the stage job, but the changes won't reflect in production. Stage should be re-run in the event of an error before running in prod to verify the correction of an error.
See Airflow's documentation on re-running DAGs for more information and implementation details.
To see the code for the merino_jobs DAG, visit the telemetry-airflow repo. The source for the job is also in the 'code' tab in the airflow console.
To see the Wikipedia Indexer code that is run when the job is invoked, visit Merino jobs/wikipedia_indexer.
Merino Jobs Operations
CSV Remote Settings Uploader Job
The CSV remote settings uploader is a job that uploads suggestions data in a CSV file to remote settings. It takes two inputs:
- A CSV file. The first row in the file is assumed to be a header that names the fields (columns) in the data.
- A Python module that validates the CSV contents and describes how to convert it into suggestions JSON.
If you're uploading suggestions from a Google sheet, you can export a CSV file from File > Download > Comma Separated Values (.csv). Make sure the first row in the sheet is a header that names the columns.
Uploading suggestions (Step by step)
If you're uploading a type of suggestion that the uploader already supports,
skip to Running the uploader below. If you're not sure
whether it's supported, check in the merino/jobs/csv_rs_uploader/ directory
for a file named similarly to the type.
To upload a new type of suggestion, follow the steps below. In summary, first you'll create a Python module that implements a model for the suggestion type, and then you'll run the uploader.
1. Create a Python model module for the new suggestion type
Add a Python module to merino/jobs/csv_rs_uploader/. It's probably easiest to
copy an existing model module like mdn.py, follow along with the steps here,
and modify it for the new suggestion type. Name the file according to the
suggestion type.
This file will define the model of the new suggestion type as it will be serialized in the output JSON, perform validation and conversion of the input data in the CSV, and define how the input data should map to the output JSON.
2. Add the Suggestion class
In the module, implement a class called Suggestion that derives from
BaseSuggestion in merino.jobs.csv_rs_uploader.base or
RowMajorBaseSuggestion in merino.jobs.csv_rs_uploader.row_major_base.
BaseSuggestion class will be the model of the new suggestion type.
BaseSuggestion itself derives from Pydantic's BaseModel, so the validation
the class will perform will be based on Pydantic, which is used
throughout Merino. BaseSuggestion is implemented in base.py. If the CSV data
is row-major based, please use RowMajorBaseSuggestion,
3. Add suggestion fields to the class
Add a field to the class for each property that should appear in the output JSON
(except score, which the uploader will add automatically). Name each field as
you would like it to be named in the JSON. Give each field a type so that
Pydantic can validate it. For URL fields, use HttpUrl from the pydantic
module.
4. Add validator methods to the class
Add a method annotated with Pydanyic's @field_validator decorator for each field.
Each validator method should transform its field's input value into an appropriate output value and raise a ValueError if the input value is invalid.
Pydantic will call these methods automatically as it performs validation.
Their return values will be used as the values in the output JSON.
BaseSuggestion implements two helpers you should use:
_validate_str()- Validates a string value and returns the validated value. Leading and trailing whitespace is stripped, and all whitespace is replaced with spaces and collapsed. Returns the validated value._validate_keywords()- The uploader assumes that lists of keywords are serialized in the input data as comma-delimited strings. This helper method takes a comma-delimited string and splits it into individual keyword strings. Each keyword is converted to lowercase, some non-ASCII characters are replaced with ASCII equivalents that users are more likely to type, leading and trailing whitespace is stripped, all whitespace is replaced with spaces and collapsed, and duplicate keywords are removed. Returns the list of keyword strings.
5. Implement the class methods
For suggestion created from row-major based CSV, should add a @classmethod to
Suggestion called row_major_field_map(). It should return a dict that maps
from field (column) names in the input CSV to property names in the output JSON.
Otherwise, should add a @classmethod to Suggestion called
csv_to_suggestions(). It should return suggestion array created from passed CSV
reader.
6. Add a test
Add a test file to tests/unit/jobs/csv_rs_uploader/. See test_mdn.py as an
example. The test should perform a successful upload as well as uploads that
fail due to validation errors and missing fields (columns) in the input CSV.
utils.py in the same directory implements helpers that your test should use:
do_csv_test()- Makes sure the uploader works correctly during a successful upload. It takes either a path to a CSV file or alist[dict]that will be used to create a file object (StringIO) for an in-memory CSV file. Prefer passing in alist[dict]instead of creating a file and passing a path, since it's simpler.do_error_test()- Makes sure a given error is raised when expected. UseValidationErrorfrom thepydanticmodule to check validation errors andMissingFieldErrorfrommerino.jobs.csv_rs_uploaderto check input CSV that is missing an expected field (column).
7. Run the test
$ MERINO_ENV=testing uv run pytest tests/unit/jobs/csv_rs_uploader/test_foo.py
See also the main Merino development documentation for running unit tests.
8. Submit a PR
Once your test is passing, submit a PR with your changes so that the new suggestion type is committed to the repo. This step isn't necessary to run the uploader and upload your suggestions, so you can come back to it later.
9. Upload!
See Running the uploader.
Running the uploader
Run the following from the repo's root directory to see documentation for all
options and their defaults. Note that the upload command is the only command
in the csv-rs-uploader job.
uv run merino-jobs csv-rs-uploader upload --help`
The uploader takes a CSV file as input, so you'll need to download or create one first.
Here's an example that uploads suggestions in foo.csv to the remote settings
dev server:
uv run merino-jobs csv-rs-uploader upload \
--server "https://remote-settings-dev.allizom.org/v1" \
--bucket main-workspace \
--csv-path foo.csv \
--model-name foo \
--record-type foo-suggestions \
--auth "Bearer ..."
Let's break down each command-line option in this example:
--server- Suggestions will be uploaded to the remote settings dev server--bucket- Themain-workspacebucket will be used--csv-path- The CSV input file isfoo.csv--model-name- The model module is namedfoo. Its path within the repo would bemerino/jobs/csv_rs_uploader/foo.py--record-type- Thetypein the remote settings records created for these suggestions will be set tofoo-suggestions. This argument is optional and defaults to"{model_name}-suggestions"--auth- Your authentication header string from the server. To get a header, log in to the server dashboard (don't forget to log in to the Mozilla VPN first) and click the small clipboard icon near the top-right of the page, after the text that shows your username and server URL. The page will show a "Header copied to clipboard" toast notification if successful.
Setting suggestion scores
By default all uploaded suggestions will have a score property whose value is
defined in the remote_settings section of the Merino config. This default can
be overridden using --score <number>. The number should be a float between 0
and 1 inclusive.
Other useful options
--dry-run- Log the output suggestions but don't upload them. The uploader will still authenticate with the server, so--authmust still be given.
Structure of the remote settings data
The uploader uses merino/jobs/utils/chunked_rs_uploader.py to upload the
output suggestions. In short, suggestions will be chunked, and each chunk will
have a corresponding remote settings record with an attachment. The record's ID
will be generated from the --record-type option, and its type will be set to
--record-type exactly. The attachment will contain a JSON array of suggestion
objects in the chunk.
Merino Jobs Operations
Geonames Uploader Job
The geonames uploader is a job that uploads geographical place data from geonames.org to remote settings. This data is used by the Suggest client to recognize place names and relationships for certain suggestion types like weather suggestions.
The job consists of a single command called upload. It uploads two types of
records:
- Core geonames data (geonames)
- Alternate names (alternates)
Core geonames data includes places' primary names, numeric IDs, their countries
and administrative divisions, geographic coordinates, population sizes, etc.
This data is derived from the main geoname table described in the geonames
documentation.
A single place and its data is referred to as a geoname.
Alternate names are the different names associated with a geoname. A single geoname can have many alternate names since a place can have many different variations of its name. For example, New York City can be referred to as "New York City," "New York," "NYC," "NY", etc. Alternate names also include translations of the geoname's name into different languages. In Spanish, New York City is "Nueva York."
Alternate names are referred to simply as alternates.
Usage
uv run merino-jobs geonames-uploader upload \
--rs-server 'https://remote-settings-dev.allizom.org/v1' \
--rs-bucket main-workspace \
--rs-collection quicksuggest-other \
--rs-auth 'Bearer ...'
This will upload data for the countries and client locales that are hardcoded by the job.
Geonames records
Each geonames record corresponds to a partition of geonames within a given country. A partition has a lower population threshold and an optional upper population threshold, and the geonames in the partition are the geonames in the partition's country with population sizes that fall within that range. The lower threshold is inclusive and the upper threshold is exclusive.
If a partition has an upper threshold, its record's attachment contains its
country's geonames with populations in the range [lower, upper), and the
record's ID is geonames-{country}-{lower}-{upper}.
If a partition does not have an upper threshold, its attachment contains
geonames with populations in the range [lower, infinity), and the record's ID is
geonames-{country}-{lower}.
country is an ISO 3166-1 alpha-2
code like US, GB, and CA. lower and upper are in thousands and
zero-padded to four places.
A partition can have a list of client countries, which are are added to its record's filter expression so that only clients in those countries will ingest the partition's record.
Partitions serve a couple of purposes. First, they help keep geonames attachment sizes small. Second, they give us control over the clients that ingest a set of geonames. For example, we might want clients outside a country to ingest only its large, well known geonames, while clients within the country should ingest its smaller geonames.
If there are no geonames with population sizes in a partition's range, no record will be created for the partition.
Types of geonames
Three types of geonames can be included in each attachment: cities, administrative divisions, and countries. Administrative divisions correspond to things like states, provinces, territories, and boroughs. A geoname can have up to four administrative divisions, and the meaning and number of divisions depends on the country and can even vary within a country.
Example geonames record IDs
geonames-US-0050-0100- US geonames with populations in the range [50k, 100k)
geonames-US-1000- US geonames with populations in the range [1m, infinity)
Alternates records
Each alternates record corresponds to a single geonames record and language. Since a geonames record corresponds to a country and partition, that means each alternates record corresponds to a country, partition, and language. The alternates record contains alternates in the language for the geonames in the geonames record.
The ID of an alternates record is the ID of its corresponding geonames record with the language code appended:
geonames-{country}-{lower}-{upper}-{language}geonames-{country}-{lower}-{language}(for geonames records without an upper threshold)
language is a language code as defined in the geonames alternates data. There
are generally three types of language codes in the data:
- A two-letter ISO 639
language code, like
en,es,pt,de, andfr - A locale code combining an ISO 639 language code with an
ISO 3166-1 alpha-2 country
code, like
en-GB,es-MX, andpt-BR - A geonames-specific pseudo-code:
abbr- Abbreviations, like "NYC" for New York Cityiata- Airport codes, like "PDX" for Portland Oregon USA- Others that we generally don't use
The input to the geonames uploader job takes Firefox locale codes, and the job automatically converts each locale code to a set of appropriate geonames language codes. Alternates record IDs always include the geonames language code, not the Firefox locale code (although sometimes they're the same).
If a geonames record includes client countries (or in other words has a filter expression limiting ingest to clients in certain countries), the corresponding alternates record for a given language will have a filter expression limiting ingest to clients using a locale that is both valid for the language and supported within the country.
If a geonames record does not include any client countries, then the corresponding alternates record will have a filter expression limiting ingest to clients using a locale that is valid for the language.
The supported locales of each country are defined in
CONFIGS_BY_COUNTRY.
Alternates records for the abbr (abbreviations) and iata (airport codes)
pseudo-language codes are automatically created for each geonames partition,
when abbr and iata alternates exist for geonames in the parition.
Excluded alternates
The job may exclude selected alternates in certain cases, or in other words it may not include some alternates you expect it to. To save space in remote settings, alternates that are the same as a geoname's primary name or ASCII name are usually excluded.
Also, it's often the case that a partition does not have any alternates at all, or any alternates in a given language.
Example alternates record IDs
geonames-US-0050-0100-en- English-language alternates for US geonames with populations in the range [50k, 100k)
geonames-US-0050-0100-en-GB- British-English-language alternates for US geonames with populations in the range [1m, infinity)
geonames-US-1000-de- German-language alternates for US geonames with populations in the range [1m, infinity)
geonames-US-1000-abbr- Abbreviations for US geonames with populations in the range [1m, infinity)
geonames-US-1000-iata- Airport codes for US geonames with populations in the range [1m, infinity)
Country and locale selection
Because the geonames uploader is a complex job and typically uploads a lot of data at once, it hardcodes the selection of countries and Firefox locales. This means that, if you want to make any changes to the records that are uploaded, you'll need to modify the code, but the tradeoff is that all supported countries and locales are listed in one place, you don't need to run the job more than once per upload, and there's no chance of making mistakes on the command line.
The job does not re-upload unchanged records by default.
The selection of countries and locales is defined in the CONFIGS_BY_COUNTRY
dict in the job's __init__.py. Here are example entries for Canada and the US:
CONFIGS_BY_COUNTRY = {
"CA": CountryConfig(
geonames_partitions=[
Partition(threshold=50_000, client_countries=["CA"]),
Partition(threshold=250_000, client_countries=["CA", "US"]),
Partition(threshold=500_000),
],
supported_client_locales=EN_CLIENT_LOCALES + ["fr"],
),
"US": CountryConfig(
geonames_partitions=[
Partition(threshold=50_000, client_countries=["US"]),
Partition(threshold=250_000, client_countries=["CA", "US"]),
Partition(threshold=500_000),
],
supported_client_locales=EN_CLIENT_LOCALES,
),
}
Each entry maps an ISO 3166-1 alpha-2 country code to data for the country. The data includes two properties:
geonames_partitionsdetermines the geonames records that will be created for the countrysupported_client_localescontributes to the set of languages for which alternates records will be created, not only for the country but for all countries inCONFIGS_BY_COUNTRY
geonames_partitions
geonames_partitions is a list of one or more partitions.
Each partition defines its lower population threshold and client countries. The
upper threshold is automatically calculated from the partition with the
next-largest threshold.
Client countries should be defined for all partitions except possibly the last.
If the last partition doesn't include client_countries, its record won't have
a filter expression, so it will be ingested by all clients regardless of
country.
In the example CONFIGS_BY_COUNTRY above, US geonames will be partitioned into
three records:
geonames-US-0050-0100- US geonames with populations in the range [50k, 100k) that will be ingested
only by US clients. Its filter expression will be
env.country in ['US']
- US geonames with populations in the range [50k, 100k) that will be ingested
only by US clients. Its filter expression will be
geonames-US-0100-0500- US geonames with populations in the range [100k, 500k) that will be ingested
by US and Canadian clients. Its filter expression will be
env.country in ['CA', 'US']
- US geonames with populations in the range [100k, 500k) that will be ingested
by US and Canadian clients. Its filter expression will be
geonames-US-0500- US geonames with populations in the range [500k, infinity) that will be ingested by all clients. It won't have a filter expression.
supported_client_locales
supported_client_locales is a list of Firefox locales. The job will convert
the locales to geonames alternates languages and create one alternates record
per geoname record per country per language (generally -- see the caveat about
excluded alternates).
Note that supported_client_locales is not necessarily a list of all
conceivable locales for a country. It's only a list of locales that need to be
supported in the country. In the example CONFIGS_BY_COUNTRY above, the entry
for Canada includes both English and French locales. If you didn't need to
support Canadian clients using the fr locale, you could leave out fr. If you
did leave out fr but then added a CONFIGS_BY_COUNTRY entry for France, which
presumably would include support for the fr locale, then French-language
alternates for all countries in CONFIGS_BY_COUNTRY would be uploaded anyway,
and Canadian clients using the fr locale would ingest them even though fr
wasn't listed as a supported Canadian locale.
The example CONFIGS_BY_COUNTRY uses EN_CLIENT_LOCALES, which is all English
locales supported by Firefox: en-CA, en-GB, en-US, and en-ZA. Up to 15
alternates records will be created for the three US geonames records due to the
following math:
3 US geonames records * (
`en` language
+ `en-CA` language
+ `en-GB` language
+ `en-US` language
+ `en-ZA` language
)
In reality, most of the US geonames records won't have geonames with alternates
in the en-* languages, only the en language, so it's more likely that only
the following alternates records will be created:
geonames-US-0050-0100-enenlanguage alternates for the geonames in thegeonames-US-0050-0100record. Its filter expression will beenv.locale in ['en-CA', 'en-GB', 'en-US', 'en-ZA']
geonames-US-0100-0500-enenlanguage alternates for the geonames in thegeonames-US-0100-0500record. Its filter expression will beenv.locale in ['en-CA', 'en-GB', 'en-US', 'en-ZA']
geonames-US-0500-enenlanguage alternates for the geonames in thegeonames-US-0500record. Its filter expression will beenv.locale in ['en-CA', 'en-GB', 'en-US', 'en-ZA']
- Plus maybe one or two
en-GBand/oren-CArecords
Operation
For each country in CONFIGS_BY_COUNTRY, the job performs two steps
corresponding to the two types of records:
Step 1:
- Download the country's geonames from geonames.org
- Upload the country's geonames records
- Delete unused geonames records for the country
Step 2:
- Download the country's alternates from geonames.org
- For each alternates language, upload the country's alternates records
- Delete unused alternates records for the country
The job does not re-create or re-upload records and attachments that haven't changed.
Command-line options
As with all Merino jobs, options can be defined in Merino's config files in addition to being passed on the command line.
--alternates-url-format
Format string for alternates zip files on the geonames server. Should contain a
reference to a country variable. Default value:
https://download.geonames.org/export/dump/alternatenames/{country}.zip
--force-reupload
Recreate records and attachments even when they haven't changed.
--geonames-url-format
Format string for geonames zip files on the geonames server. Should contain a
reference to a country variable. Default value:
https://download.geonames.org/export/dump/{country}.zip
--rs-dry-run
Don't perform any mutable remote settings operations.
--rs-auth auth
Your authentication header string from the server. To get a header, log in to the server dashboard (don't forget to log in to the Mozilla VPN first) and click the small clipboard icon near the top-right of the page, after the text that shows your username and server URL. The page will show a "Header copied to clipboard" toast notification if successful.
--rs-bucket bucket
The remote settings bucket to upload to.
--rs-collection collection
The remote settings collection to upload to.
--rs-server url
The remote settings server to upload to.
Tips
Use attachment sizes to help decide population thresholds
Attachment sizes for geonames and alternates records can be quite large since
this job makes it easy to select a large number of geonames. As you decide on
population thresholds, you can check potential attachment sizes without making
any modifications by using --rs-dry-run with a log level of INFO like this:
MERINO_LOGGING__LEVEL=INFO \
uv run merino-jobs geonames-uploader upload \
--rs-server 'https://remote-settings-dev.allizom.org/v1' \
--rs-bucket main-workspace \
--rs-collection quicksuggest-other \
--rs-auth 'Bearer ...' \
--rs-dry-run
Look for "Uploading attachment" in the output.
You can make the log easier to read if you have jq
installed. Use the mozlog format and pipe the output to jq ".Fields.msg"
like this:
MERINO_LOGGING__LEVEL=INFO MERINO_LOGGING__FORMAT=mozlog \
uv run merino-jobs geonames-uploader upload \
--rs-server 'https://remote-settings-dev.allizom.org/v1' \
--rs-bucket main-workspace \
--rs-collection quicksuggest-other \
--rs-auth 'Bearer ...' \
--rs-dry-run \
| jq ".Fields.msg"
Merino ADRs
This directory archives all the Architectural Decision Records (ADRs) for Merino.
Locust vs k6; Merino-py Performance Test Framework
- Status: Accepted
- Deciders: Nan Jiang, Raphael Pierzina & Katrina Anderson
- Date: 2023-02-21
Context and Problem Statement
Performance testing for the Rust version of Merino was conducted with the Locust test framework and focused on the detection of HTTP request failures. During the migration of Merino from Rust to Python, performance testing was conducted with k6 and focused on the evaluation of request latency. Going forward a unified performance testing solution is preferred, should the test framework be Locust or k6?
Decision Drivers
- The test framework supports the current load test design, a 10-minute test run with an average load of 1500RPS (see Merino Load Test Plan)
- The test framework measures HTTP request failure and client-side latency metrics
- The test framework is compatible with the Rapid Release Model for Firefox Services
initiative, meaning:
- It can execute through command line
- It can signal failures given check or threshold criteria
- It can be integrated into a CD pipeline
- It can report metrics to Grafana
- The members of the DISCO and ETE teams are able to contribute to and maintain load tests written with the test framework
Considered Options
- A. Locust
- B. k6
Decision Outcome
Chosen option:
- A. Locust
Both k6 and Locust are able to execute the current load test design, report required metrics and fulfill the Rapid Release Model for Firefox Services initiative; However, Locust's Python tech stack ultimately makes it the better fit for the Merino-py project. In-line with the team's single repository direction (see PR), using Locust will:
- Leverage existing testing, linting and formatting infrastructure
- Promote dependency sharing and code re-use (models & backends)
Pros and Cons of the Options
A. Locust
Locust can be viewed as the status quo option, since it is the framework that is currently integrated into the Merino-py repository and is the basis for the CD load test integration currently underway (see DISCO-2113).
Pros
- Locust has a mature distributed load generation feature and can easily support a 1500 RPS load
- Locust has built-in RPS, HTTP request failure and time metrics with customizable URL break-down
- Locust scripting is in Python
- Locust supports direct command line usage
- Locust is used for load testing in other Mozilla projects and is recommended by the ETE team
Cons
- Locust is 100% community driven (no
- commercial business), which means its contribution level can wane
- Preliminary research indicates that reporting metrics from Locust to Grafana requires the creation of custom code, a plugin or a third party integration
B. k6
For the launch of Merino-py, performance bench-marking was conducted using a k6 load test script (see Merino Explorations). This script was reused from the Merino rewrite exploration effort and has proven successful in assessing if Merino-py performance achieves the target p95 latency threshold, effecting preventative change (See PR). k6's effectiveness and popularity amongst team members is an incentive to pause and evaluate if it is a more suitable framework going forward.
Pros
- k6 is an open-source commercially backed framework with a high contribution rate
- k6 is built by Grafana Labs, inferring easy integration with dashboards
- k6 has built-in RPS, HTTP request failure and time metrics with customizable URL break-down
- k6 supports direct command line usage
- k6 is feature rich, including built-in functions to generate pass/fail results and create custom metrics
Cons
- The k6 development stack is in JavaScript/TypeScript. This means:
- Modeling and backend layer code would need to be duplicated and maintained
- Linting, formatting and dependency infrastructure would need to be added and maintained
- k6 has an immature distributed load generation feature, with documented
limitations
- k6 runs more efficiently than other frameworks, so it may be possible to achieve 1500 RPS without distribution
Links
Merino Suggest API Response Structure
- Status: accepted
- Deciders: Michelle Tran, Lina Butler, Nan Jiang, Wil Stuckey, Drew Willcoxon, Taddes Korris, Tiffany Tran
- Date: 2023-04-20
Context and Problem Statement
As Merino continues to add more suggestions,
suggestion providers are going to have to return all sorts of
data to the clients that are bespoke to the particular suggestion.
For instance, weather suggestion returns a temperature.
Currently, we do not have a strategy to manage these bespoke pieces of data
which results in them returned at the top level of the suggestion object.
However, this will pose a problem when
- names of fields are shared between providers, but have different semantics
(i.e.
ratingmay be a decimal value between 0-1 in one type, and a "star" integer rating between 1-5 in another) - the API is unclear about what will necessarily exist, and what is optional, which leads to client confusion about the contract
So, this ADR is to make a decision on how we want to handle provider specific fields going forward.
Decision Drivers
In rough order of importance:
- Explicitness of Ownership - i.e. the
ratingfield belongs to theaddonsprovider - Compatibility with [JSON] Schema Validation
- Adherence to the Fx Suggest Design Framework
- Backwards Compatibility with Current Schema
Considered Options
- A. Continue to add to Top Level with Optional Fields
- B. Custom Details Field for Bespoke Provider Fields
- B.5 Custom Details Field without the Provider Nesting
- C. Custom Details Field for a "Type"
- D. Component Driven
custom_details
Decision Outcome
Chosen option: B
We will also not increase the version number of the API for this ADR. So, going forward, we will encode option B into the response design without changing the existing providers. This means that the following providers will not have their bespoke fields removed from top level:
- AdM Provider
- Top Picks Provider
- Weather Provider
- Wikipedia Provider
- WikiFruit Provider
However, this does not preclude these providers from duplicating the fields
to custom_details in the v1 API.
Positive Consequences of Option B
- Clear isolation of fields that belong together (i.e. grouped by provider).
- Clear ownership of fields through the structure.
- Simpler validation logic than other options due to less need for conditionals.
Negative Consequences of Option B
- Potentially some redundancy caused by extra nesting.
- Might not be as flexible with a provider that returns different fields based on what type of suggestion it is.
Positive Consequences of not Increasing API Version
- We do not have to worry about migrating Firefox (and other clients) into the new format. The migration is going to be quite a lot of extra work that adds little benefits (other than consistency of design, it doesn't add more features nor improve any known time sinks with development).
- Do not have to support 2 versions of the API.
Negative Consequences of not Increasing API Version
- Some inconsistencies with how providers add fields to the response. We will likely want to resolve this as we migrate to v2, but it's a known issue at the moment.
- Might be missing an opportune time to migrate, as features are currently not out yet which means the flexibility for change is higher.
Pros and Cons of the Options
A. Continue to add to Top Level with Optional Fields
This is the status quo option.
We will continue to append bespoke values to the top level suggestion,
and ensure that they're optional.
We can continue to use the provider to signal what fields exists
and how they should be parsed.
For example, we can specify 2 different types of rating,
and hence 2 validation strategy for it,
based off of which provider is specified.
Example:
{
"suggestions": [
{
...
"provider": "addons",
"rating": "4.123",
...
},
{
...
"provider": "movies",
"rating": 0.123,
...
},
...
],
...
}
The partial JSON Schema validation will look something like:
{
"type": "object",
"properties": {
"provider": {
"type": "string"
}
},
"required": ["provider"],
"allOf": [
{
"if": {
"properties": {
"provider": {
"const": "addons"
}
}
},
"then": {
"properties": {
"rating": {
"type": "string"
}
},
"required": [
"rating"
]
}
},
{
"if": {
"properties": {
"provider": {
"const": "movies"
}
}
},
"then": {
"properties": {
"rating": {
"type": "number"
}
},
"required": [
"rating"
]
}
}
]
}
Pros
- Can specify specific validation per provider.
- Merino is still kind of immature, so it still might be too early to think about design.
- Less nesting in the models (resulting in less complexity).
- Currently, backwards compatible as we don't have to do anything to existing providers, as this follows the existing patterns.
Cons
- Lack of isolation for bespoke fields;
ratingsis coupled with 2 specific providers, and by just looking at the response, it's not clear that they are related. - Not clear what is shared between all suggestions, vs. what is bespoke to specific provider.
- It is not obvious that the
providerfield should signal how you should perform validation. In other words, there is a contextual dependency on the JSON structure of suggestion based onprovider.
B. Custom Details Field for Bespoke Provider Fields
We introduce a custom_details field that uses a provider name as key
to an object with the bespoke values to that provider.
Example:
{
"suggestions": [
{
...
"provider": "addons",
"custom_details": {
"addons": {
"rating": "4.7459"
}
}
},
...
],
...
}
The specific fields in custom_details will all be optional (i.e. addons will be an optional key)
but the shape of what goes in addons can be more strict (i.e. addons require a rating field).
A partial schema specification for the above might look like1:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "Suggest API Response v1",
"description": "Response for /api/v1/suggest",
"type": "object",
"properties": {
"provider": {
"description": "id for the provider type",
"type": "string"
},
"custom_details": {
"type": "object",
"properties": {
"addons": {
"type": "object",
"description": "Custom Addon Fields",
"properties": {
"rating": {
"type": "number"
}
},
"required": ["rating"]
}
}
}
},
"required": ["provider"]
}
Can play with JSON schema in https://www.jsonschemavalidator.net/
Pros
- Can specify specific validation per provider.
- Clear ownership of
ratingtoaddonsvia structure. - Fields outside of
custom_detailscan be fields that are more universal across suggestions. These fields can potentially be correlated directly to the Fx Suggest Design Framework (i.e.context_label,url,title,description, etc.). - Having a clear distinction for Fx Suggest Design Framework fields vs. bespoke fields makes this more backwards compatible, as the fields in the Design Framework can render the default suggestion case for clients who haven't upgraded their clients.
Cons
- We'll likely need to migrate existing providers at some point. But in the meantime, some fields will not follow convention to maintain backwards compatibility.
- Extra nesting inside of
custom_details.
B.5 Custom Details Field without the Provider Nesting
This is exactly like B, except that we remove the extra nesting.
So, in the example above, we can remove the extra addons object to get:
{
"suggestions": [
{
...
"provider": "addons",
"custom_details": {
"rating": "4.7459"
}
},
...
],
...
}
The validation of the contents of custom_details will look more like A.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "Suggest API Response v1",
"description": "Response for /api/v1/suggest",
"type": "object",
"properties": {
"provider": {
"description": "id for the provider type",
"type": "string"
}
},
"required": [
"provider"
],
"if": {
"properties": {
"provider": {
"const": "addons"
}
}
},
"then": {
"properties": {
"custom_details": {
"description": "Custom Details Specific for Addons",
"type": "object",
"properties": {
"rating": {
"type": "string"
}
},
"required": [
"rating"
]
}
},
"required": ["custom_details"]
}
}
Pros
- Can specify specific validation per provider.
- Fields outside of
custom_detailscan be fields that are more universal across suggestions. These fields can potentially be correlated directly to the Fx Suggest Design Framework (i.e.context_label,url,title,description, etc.). - Having a clear distinction for Fx Suggest Design Framework fields vs. bespoke fields makes this more backwards compatible, as the fields in the Design Framework can render the default suggestion case for clients who haven't upgraded their clients.
- Less nesting in the response than B
Cons
- We'll likely need to migrate existing providers at some point. But in the meantime, some fields will not follow convention to maintain backwards compatibility.
- The relationship between
providerandcustom_detailsis more implicit, than explicit. - This has a lot of the same cons as Option A because validation is done similarly.
C. Custom Details Field for a "Type"
This is similar to option B, except that we want to introduce a new type field
to differentiate it from the provider.
The custom_details will be keyed by this type, rather than the provider name.
These types are kind of analogous to a rendering component,
as they will likely be used to specify a specific rendering path in the client.
Example:
{
"suggestions": [
{
...
"provider": "addons",
"type": "addons_type",
"custom_details": {
"addons_type": {
"rating": "4.7459"
}
}
},
...
],
...
}
Pros
- All the pros for B applies here
- Can decouple the
custom_detailsfromprovider. This will be helpful for potentially sharing thetypewith other suggestions produced by different providers. For instance, we may want this to specify different rendering paths in the client (i.e. a "top picks" type to be shared betweenaddonsandtop_picksproviders, as there's many shared fields because they're rendered similarly).
Cons
- All the cons for B applies here
- Potentially over-engineering for
type, as it's use is currently hypothetical.
D. Component Driven custom_details
This solution will model distinct UI components in the custom_details section.
For example, if the addons provider have specific UI components to render a ratings component and
a highlight_context_label, then we can specify these directly in the custom_details section.
This will assume that the client side have these specific rendering types.
Example:
{
"suggestions": [
{
...
"provider": "addons",
"custom_details": {
"ratings": {
"value": "4.7459",
"unit": "stars"
},
"highlight_context_label": {
"text": "Special Limited Time Offer!"
}
}
},
...
],
...
}
Pros
- Can share custom components with schema validation.
- Backwards compatible with clients who don't have the necessary components to render. It will just use the default renderer via the Fx Suggest Design Framework
Cons
- We currently don't have a sophisticated Component Design Framework, so this is probably overengineering.
- This tightly couples the API to the design framework of Desktop Firefox, which makes the fields potentially less relevant to other clients.
Links
Streamline Test Coverage of Third-Party Integrations
- Status: Accepted
- Deciders: Nan Jiang & Katrina Anderson
- Date: 2024-01-24
Context and Problem Statement
In 2024, it is anticipated that Merino will expand to be consumed by a greater set of Firefox surfaces and to include more content providers. This will challenge the current feature test strategy, which has shown weakness in detecting incompatibilities with third-party integrations. Examples:
The current test approach uses a combination of unit, integration, and contract feature tests, where third-party integrations such as cloud services, data storage services, and external API integrations are test doubled in the unit and integration tests and emulated with Docker containers in contract tests. While test doubles might be easier to work with, they lack the accuracy of working with real dependencies in terms of matching the production environment and covering all the integration surfaces and concerns in tests.
Despite the potential to test with third-party integrations in contract tests, developers have refrained due to their lack of familiarity with Docker and CI tooling, as well as their belief in a poor return on investment for the time and effort required to create and maintain contract tests for experimental features.
Given the Merino service context, which has a rapid development pace and a high risk tolerance, is there a way to streamline the test strategy while ensuring robustness against third-party integrations?
Decision Drivers
1. Usability & Skill Transferability
Ease-of-use is the key criterion when we assess a tool for testing. The test strategy should prefer tools that require less effort and time to acquire proficiency. It should be easy to learn and work with. Ideally, any skills or knowledge acquired should be applicable across current contexts or for future scenarios.
2. Maturity & Expandability
The test strategy and tooling should be able to handle known third-party Merino dependencies in tests with a reasonable belief that it will cover future growth. Known third-party dependencies include: REST APIs, Remote Settings, GCP Cloud Storage, Redis, and Elasticsearch. Future dependencies include: relational DBMS such as PostgreSQL and other GCP cloud services such as Pub/Sub.
3. Cost Efficiency
The worker hours and tooling expenditures associated with the implementation and execution of the test strategy should ensure the profitability of Merino.
Considered Options
- A. Yes. Expand the Scope of Integration Tests Using Dependency Docker Containers (Testcontainers)
- B. Yes. Reduce the Dependency Overhead in Tests Using Development and Stage Environments
- C. No. Fulfill the Current Test Strategy with Contract Test Coverage (Status quo)
Decision Outcome
Chosen option: A
Overall, we believe that increasing the scope of integration tests to verify third-party integrations with Testcontainers will be the most effective and sustainable way forward. Testcontainers' "Test dependencies as code" approach best fulfills the Usability & Skill Transferability and Maturity & Expandability decision drivers and long-term would prove to be the most Cost Efficient option.
We expect there to be initial labour costs to integrating Testcontainers, but anticipate that moving more verification responsibility to the integration test layer will be more accessible for developers and will reduce bugs found between Merino and third-party integrations.
Testcontainers is a widely adopted container-based test platform that supports a wide range of programming languages including Python and Rust, which are popular at Mozilla and there is indication that Testcontainers would have applicability across services in PXI. Given the success of Rapid Release and other experiments in Merino, it's a good candidate to use in Merino first as a pilot test. Should we find any issues or unsoundness about it, we can always revert the decision in the future.
Pros and Cons of the Options
A. Yes. Expand the Scope of Integration Tests Using Dependency Docker Containers (Testcontainers)
A preference for the unit and integration feature test layers in Merino has emerged over time. These test layers are white-box, which means developers can more easily set up program environments to test either happy paths or edge cases. In addition, tooling for debugging and measuring code coverage is readily available in these layers.Testcontainers can be used to increase the scope of integration tests, covering the backend layer logic and network communication with third-party integrations, the current test strategy's point of weakness.
Pros
- Testcontainers works with any Docker image and has numerous pre-built modules. Almost all the existing dependencies (or their close emulators) of Merino can be run as Docker containers. As a result, we can use real dependencies in Merino's tests as opposed to test doubles
- Testcontainers allows developers to programmatically manage the lifecycle of containers in the test code. This simplifies its usage for developers, who will not need to run any Docker commands separately for testing
- Testcontainers, which has recently been acquired by Docker, is fairly mature and supports many popular programming languages. There are also a large number of community maintained clients available for popular services such as PostgreSQL, Redis, Elasticsearch, etc.
- Testcontainers is lightweight and sandboxed, meaning service resources aren't shared and are cleaned up automatically, promoting test isolation and parallelization
- Docker-compose is also supported by Testcontainers, facilitating use of multiple dependency containers for more complex test cases
- Testcontainers supports Python, Rust and Javascript languages and works well with their respective test frameworks PyTest, Cargo-Test and Jest
Cons
- A Docker runtime is required to run all the tests that depend on Testcontainers. Docker is already setup in CI, but developers may need to install a Docker runtime locally
- Integration tests cannot be run completely offline as Docker images need to be downloaded first
- Developers will need to understand more about how to configure and work with dependency containers. The development community has many popular services out of the box, but developers would still need to know and do more than what's required when using test doubles
- It could be challenging to provision test fixtures for the underlying containers. Feeding the fixture data into the containers could be complex
- Developers need to ensure version consistency across the development, testing, and production environments in the integration test layer
- For third-party API integrations, if the provider doesn't provide a Docker image for their API, Testcontainers alone will not help us much. It's possible to use fake API container generators, such as Wiremock, but it comes with its own complexities
- Implementation of Testcontainers would require refactoring of integration tests, including the removal of mocks and fixtures
B. Yes. Reduce the Dependency Overhead in Tests Using Development and Stage Environments
Using Merino's staging environment and third-party development resources in tests has been considered. This would effectively cover the current test strategy's weakness with third-party integrations without the cost and complexity involved with setting up test doubles or dependency containers. However, this approach has a key challenge in how to share the stage environment across all the test consumers (devs & CI) as most of the services do not support multi-tenant usage and would require a significant amount of effort to support resource isolation.
Pros
- Best matches the production environment
- Doesn't need extra effort to create test doubles or dependencies for testing
Cons
- Tests cannot be run offline since they would require a network connection to interact with development and stage environments
- This option breaks the Testing Guidelines & Best Practices for Merino, which require tests to be isolated and repeatable. A dependency on shared network resources will almost certainly lead to test flake, reducing the confidence in the test suite
- Test execution speeds would be negatively impacted, due to the lack of sandboxing, which enables parallel test runs
C. No. Fulfill the Current Test Strategy with Contract Test Coverage (Status quo)
The current test strategy, which relies on the contract tests to verify the interface between Merino and third-party dependencies, has not been fully implemented as designed. The missing coverage explains the current test strategy's weakness. Examples:
- DISCO-2032: Weather Contract Tests
- DISCO-2324: Add a merino-py contract test that interacts with a real Redis instance
- DISCO-2055: Dynamic Wikipedia Contract Tests
Pros
- The most cost-effective solution, at least in the short term, since the test framework and Docker dependencies are set up and integrated into CI
- The unit and integration feature test layers remain simple by using test doubles
Cons
- The black-box nature of contract tests makes it harder to set up the environmental conditions required to enable testing edge cases
- Adding dependency containers is complex, often requiring developers to have advanced knowledge of Docker and CI vendors (e.g. CircleCI)
- There is a high level of redundancy between unit, integration, and contract tests that negatively impacts development pace
Open Questions
- How to test 3rd party API integrations? We have two options for consideration: Either use generic API mocking frameworks or keep status quo and rely on other means (e.g. observerbility) to capture API breakages. They both have pros and cons and warrant a separate ADR to discuss in detail
Links
Assure Endpoint Functionality and Load Test Suite Integrity with Default Load Tests
- Status: Accepted
- Deciders: Katrina Anderson & Nan Jiang
- Date: 2024-11-04
Context and Problem Statement
Currently, load tests for the Merino service are executed on an opt-in basis, requiring contributors
to use their judgement to execute load tests as part of a deployment to production. Contributors
opt-in to load testing by including the [load test: (abort|warn)] substring in their commit
message. The abort option prevents a production deployment if the load testing fails, while the
warn option provides a warning via Slack and allows the deployment to continue in the event of
failure.
This strategy has several drawbacks:
- Load tests are run infrequently, making it difficult to establish performance trends or trace regressions to specific changes
- Relying on contributors to decide when to run load tests has proven unreliable. Developers occasionally introduce changes that silently break the load testing suite, particularly when new dependencies are added (Example: DISCO-3026)
- The SRE team currently lacks the capacity to implement a weekly load test build (Example:
SVCSE-2236)
- On a related note, due to the same capacity issues, the SRE team has indicated that a smoke test suite can't be integrated into the CD pipeline until Merino moves from GCP v1 to GCP v2, leaving a gap in coverage (Example DISCO-2861)
Given these drawbacks, is there a way to provide greater consistency and more reliable feedback on the performance of Merino's API endpoints and the health of its load test suite?
Decision Drivers
Resource Consumption
The solution should ensure API quotas with third-party providers, such as AccuWeather, are
respected.
Load Test Break Detection
The solution should notify contributors when they introduce changes that break the load tests.
Performance Trending
The solution should enable the establishment of consistent and reliable performance trends for
Merino-py endpoints, allowing contributors to quickly identify regressions.
Deployment Efficiency
The solution should minimize delays in the deployment process while ensuring that critical issues
are flagged promptly.
Considered Options
- A. Turn on
[load test: warn]by default with opt-out option - B. Turn on
[load test: abort]by default with opt-out option - C. Weekly manual execution of load tests
- D. Status quo: Keep current strategy
Decision Outcome
Chosen option: A. Turn on [load test: warn] by default with opt-out option
Until a weekly load test run and smoke tests can be incorporated into the CD pipeline, the decision
is to turn on [load test: warn] by default and add an opt-out option, [load test: skip]. This
will provide much-needed insight into the performance and health of Merino’s API endpoints, while
giving contributors early feedback on the integrity of the load test suite. Additionally, this
approach will pave the way for the deprecation of Contract Tests, reducing overall test maintenance.
Note: The policy for documenting load test results in the Merino Load Test spreadsheet will remain unchanged. Contributors may decide when it's necessary to do so, for example when a load test fails.
Pros and Cons of the Options
A. Turn on [load test: warn] by default with opt-out option
This option would ensure that load tests run automatically during deployments, with failures
generating warnings but not blocking the deployment. Contributors would have the ability to opt-out
of load tests using a new option, [load test: skip].
Pros
- Load tests would run more frequently, providing consistent feedback on Merino API endpoints and acting as a lightweight smoke test
- Contributors would receive early warnings if their changes break the load test suite, allowing issues to be traced back to specific pull requests
- The work required to implement this change is minimal and includes:
- Modifying the smoke load test curve to minimize runtime and API resource consumption
- Updating the CircleCI configuration
- Updating documentation
Cons
- This approach would increase deployment time by approximately 10 minutes and could worsen an existing issue where concurrent merges to the main branch do not queue as expected, resulting in simultaneous deployments that may invalidate load tests
- If production deployments were to increase dramatically, there is potential to exceed 3rd party API quotas
B. Turn on [load test: abort] by default with opt-out option
This option would also ensure that load tests run automatically during deployments, but production
deployments would be blocked if the load tests fail. Contributors would have the option to opt-out
of load tests with a new option, [load test: skip].
Pros
Includes the Pros from Option A, plus:
- Ensures that broken API endpoints are not deployed to users, maintaining the integrity of the service
Cons
Includes the Cons from Option A, plus:
- Critical features and fixes may be delayed if the load tests themselves are broken, leading to unnecessary deployment blockages
C. Weekly manual execution of load tests
This option involves a member of the DISCO team manually triggering a load test on a weekly basis. The load test could be triggered via PR or manually via a bash script.
Pros
- Regular load testing would allow the team to establish meaningful performance trends
- Breaks in the load test suite would be detected within a reasonable timeframe, making them easier to trace
Cons
- This approach does not address the coverage gap for API endpoint verification during deployment
- It is time-consuming for the DISCO team, and depending on the trigger technique, it may be
error-prone
- For example, if a DISCO team member triggers the load test via bash script and forgets to tear down the GCP cluster after use, unnecessary costs will be incurred
D. Status quo: Keep current strategy
This option involves continuing with the current opt-in approach, where load tests are only run if contributors explicitly include them in their deployment process, until the SRE team can prioritize test strategy changes.
Pros
- Requires no additional work or changes to the current setup.
Cons
- Breakages in the load testing suite due to environmental, configuration, or dependency changes will continue to go undetected
- The lack of regular load tests prevents contributors from gathering sufficient data to establish meaningful performance trends
Asycnchronous Python Google Cloud Storage Client
- Status: Accepted
- Deciders: Nan Jiang, Herraj Luhano
- Date: 2025-02-04
Context and Problem Statement
The Merino application has expanded to include the /manifest endpoint that interacts with a Google Cloud Storage (GCS) bucket. Currently, Merino relies on the official Google Cloud Python client (google-cloud-storage) for interacting with GCS for weekly job runs, but this client is synchronous.
Since the /manifest endpoint handles requests in an asynchronous web environment, using a synchronous client would block the main thread, leading to performance issues. To work around this, we currently offload GCS operations to thread pool dedicated for running synchronous workloads, but this adds unnecessary complexity.
To simplify the implementation and fully leverage asynchronous capabilities, we are considering adopting talkiq/gcloud-aio-storage, a community-supported asynchronous Python client for Google Cloud Storage. This would allow us to perform GCS operations without blocking the main thread, leading to cleaner and more efficient code.
Decision Drivers
- Deteriorated performance due to
/manifestrequests blocking the main thread. - Additional complexity due to implementing custom logic for background tasks.
Considered Options
- A.
gcloud-aio-storage. - B.
google-cloud-storage(Existing official synchronous Python client).
Decision Outcome
Chosen option:
A. gcloud-aio-storage
gcloud-aio-storage appears to be the most widely used community-supported async client for Google Cloud Storage. It has fairly decent documentation, is easy to set up and use, and aligns well with Merino’s asynchronous architecture. Adopting it will simplify integration while ensuring non-blocking GCS interactions in the /manifest endpoint.
Positive Consequences
- Seamless integration with existing implementation and logic. As an async client, it comes with native async APIs to GCS, which substantially simplifies the usage of GCS in Merino. Particularly, no more offloading synchronous calls over to the thread pool.
- Easy authentication -- No extra steps needed for authentication. Uses the same logic as the exisiting sync client.
- Provides other asynch clients as well --
gcloud-aiolibrary has modules for other Google Cloud entities such asBigQuery,PubSub, e.t.c, which will be useful in the future.
Negative Consequences
- The SDK api is slightly different to the official one -- When it comes to wrapper classes and return types. Although, it supports the basic wrapper classes for entities such as
BlobandBucket, some of the types are more raw / basic. This could be seen as allowing for implementation flexibility, however, it does introduce some verbosity. - Not officially supported by Google -- Relying on community contributors for support and updates. Will have to migrate to the official async one if/when Google releases one.
- Two GCS clients -- Merino will use both the async client for the web app mode, and the official sync client for Merino jobs, which might cause confusion.
Pros and Cons of the Synchronous Client
Pros
-
Officially Supported by Google – Maintained and supported by Google, ensuring long-term reliability, security updates, and compatibility with GCS features.
-
Official Documentation & Large User Base – Extensive official documentation and a large user base, making it easier to find solutions to issues.
-
Consistent with Existing Usage – Already used in Merino’s jobs component, reducing the need to maintain multiple clients for the same service.
-
No Additional Dependencies – Avoids adding a third-party dependency, reducing potential maintenance overhead.
Cons
-
Blocks the Main Thread – The client is synchronous, which can lead to performance issues in Merino’s
/manifestendpoint by blocking request handling. -
Workarounds Add Complexity – Using background tasks to offload GCS operations introduces unnecessary complexity and potential race conditions.
-
Inconsistent with Merino’s Async Architecture – Merino is built to be asynchronous, and using a sync client requires special handling, breaking architectural consistency.
-
Potential Scalability Issues – Blocking I/O operations can slow down request processing under high load, reducing overall efficiency.
-
Misses Out on Async Benefits – Async clients improve responsiveness and throughput by allowing other tasks to execute while waiting for network responses.
Links
Suggest New Provider Integrations Endpoint Split
- Status: Rejected
- Deciders: Herraj Luhano, Nan Jiang, Drew Willcoxon, Chris Bellini, Temisan Iwere, Bastian Gruber
- Date: 2025-06-08
Context and Problem Statement
We want to review the current implementation of the suggest endpoint and determine either to continue expanding it or to introduce new endpoints to support the upcoming new suggestion providers that are "non-standard" providers.
Standard suggest providers return results based on full or partial search queries—essentially suggesting content as the user types. Examples include adm, amo, top_picks, and wikipedia.
Non-standard suggest providers return a specific result triggered by an exact keyword match. For instance, accuweather provides weather details when the user enters a city name followed by the keyword weather.
Current Implementation
Currently, all suggest providers—including third-party ones (Accuweather)—use the /suggest/ endpoint. Here's a high-level overview of the request flow for a weather suggestion:
- A request hits the
/suggestendpoint. - The following query parameters are accepted:
requestqcountryregioncityprovidersclient_variantssourcesrequest_type
The suggest() method processes the request by:
- Extracting
metrics_clientanduser_agentfrom middleware. - Removing duplicate provider names (if passed via the
providersquery param). - Creating local variables such as
languagesandgeolocationto be passed to the providers'query()methods. - Looping through each provider to:
- Construct a
SuggestionRequestobject from the query params. - Call the provider’s
validate()method. - Call the provider’s
query()method (which does all the actual processing). - Add each successful async task to a list.
- Construct a
- Performing additional logic and emitting per-request and per-suggestion metrics.
- Building a
SuggestResponseobject with a list of suggestions and other metadata. - Adding TTL and other headers to the final response.
- Returning an
ORJSONResponse.
Limitations of the Current Implementation
This implementation highlights how the /suggest endpoint is built to support a flexible, provider-agnostic flow. However, it comes with significant overhead—shared parsing logic, dynamic provider resolution, and assumptions like multi-suggestion responses —that don’t align well with the needs of upcoming providers. The problem statement asks whether we should continue extending this shared machinery or introduce new, purpose-built endpoints. Understanding the complexity and coupling in the current flow helps clarify why a new endpoint may offer a cleaner, more maintainable path forward for future provider integrations. See the Accuweather provider example below.
Accuweather Provider
The Accuweather provider currently uses this same endpoint to serve both weather suggestions and widget data. However, it's tightly coupled to all the suggest-related types, protocols, and abstractions. This coupling became especially apparent when implementing custom TTL logic for weather responses, which had to be awkwardly threaded through unrelated suggest components.
Moreover, the SuggestResponse type requires a suggestions list. But for weather—and likely for many new providers—we only return a single suggestion per request.
Future Considerations
Now that we’re planning to add 5+ new providers for the Firefox search and suggest feature, we should reconsider whether this shared approach is still appropriate. These new providers will each have their own query parameters, request/response shapes, and logic for upstream API calls and formatting.
The only requirement is that the final API response must conform to the SuggestResponse format expected by Firefox.
Decision Drivers
- Separation of entities and mental model
- Addressing the growing complex custom logic
- Ergonomics for the client-side integration
Considered Options
- A. Continue using the existing
/suggestendpoint and extend it to support new providers. - B. Create a separate endpoint for each provider, each with its own request/response handling logic.
- C. Create a single new endpoint for all non-standard providers (i.e., those that don’t follow the typical suggest flow or response shape).
Pros & Cons of Each Option
Option A
Pros
- Consistent client interface -- No need to change frontend code or contracts; clients already know how to use
/suggest. - Shared logic and infrastructure -- Leverages existing abstractions like middleware, metrics, and response formatting.
Cons
- Overgeneralized interface -- Forces all providers to conform to a common structure, even when their needs (params, shape, TTL) are different.
- Hard to scale and maintain -- Adding each new provider increases complexity and coupling, making the suggest logic harder to reason about.
Option B
Pros
- Full flexibility per provider -- Each provider can define its own request/response model and internal flow, with no need to conform to shared logic.
- Clear separation of concerns -- Isolates logic and failures per provider, making debugging and ownership more straightforward.
Cons
- Client complexity -- The frontend would need to know which endpoint to call per provider, increasing client-side branching or routing logic.
- Maintenance overhead -- More endpoints to monitor, document, test, and version over time.
Option C
Pros
- Clean separation from the legacy
/suggestlogic -- Avoids polluting the current flow with special cases while still avoiding endpoint proliferation. - Balance of structure and flexibility -- A shared endpoint can still dispatch to internal handlers, allowing each provider to have tailored logic behind a unified interface.
Cons
- Yet another endpoint to manage -- Slight increase in complexity at the infra/API gateway level.
- Internal dispatching still requires careful design -- You still need to decide how to route requests internally (e.g., by provider param) and validate inputs correctly without repeating /suggest-style logic.
Case for Option C
1. Encapsulation of Divergent Logic
The new providers will likely have custom logic around query parameters, upstream requests, and response formatting. Trying to shoehorn this into the existing /suggest flow would introduce complexity and conditionals that hurt maintainability.
A new endpoint provides a clean separation between "standard" suggest logic and custom workflows.
2. Avoids Tight Coupling
The existing implementation is tightly coupled to SuggestResponse, middleware-derived state, and other shared abstractions.
Decoupling non-standard providers from that machinery avoids repeating the friction you experienced with Accuweather (e.g., threading TTL logic and handling one-item responses in a list-based structure).
3. Simplifies Onboarding of Future Providers
With a flexible endpoint, you can tailor the request/response contract to match each provider's needs while maintaining a consistent response format for Firefox.
This reduces the amount of edge-case handling required and lowers the cognitive load for developers onboarding new providers.
4. Maintains Backward Compatibility
Keeping /suggest intact for legacy or conforming providers avoids breaking existing consumers.
You can gradually migrate providers to the new endpoint as needed.
Decision Outcome
Chosen option:
- A. Option A -- Continue using the existing
/suggestendpoint and extend it to support new providers.
Based on the discussion and feedback from the DISCO and Search & Suggest team engineers, we'll proceed with the current implementation using the existing /suggest endpoint for the new provider integrations. Since there's no pressing need to introduce a new endpoint and this approach aligns better with the client’s expectations, it makes sense to avoid unnecessary complexity for now. Down the line, we can revisit the endpoint design if needed and have a broader conversation around evolving the request/response structure to better support both legacy and new providers.
Load GCS Data via SyncedGcsBlob in Merino
- Status: Accepted
- Deciders: Bastian Gruber, Herraj Luhano, Mathijs Miermans, Nan Jiang
- Date: 2025-07-24
Context and Problem Statement
The following Merino providers load data from Google Cloud Storage (GCS):
- TopPicks - reloads suggestion data every 12 hours
- Manifest - reloads domain metadata (icons, titles, categories) every hour
- Curated Recommendations - uses
SyncedGcsBlobto check every minute and load data only when the blob is updated
TopPicks and Manifest are loaded periodically without checking whether the data was updated. This requires a longer reload time, leading to stale data, unnecessary resource use, and duplicated maintenance effort.
The existing SyncedGcsBlob class, used by the curated recommendations endpoint, periodically checks the updated timestamp of GCS blobs and reloads data only when blobs are updated, calling a callback function to parse and cache the data. However, SyncedGcsBlob currently uses Google's synchronous GCS client (google-cloud-storage), offloading synchronous calls to a thread pool to avoid blocking the main event loop (as previously addressed in ADR 0005).
Should we standardize on SyncedGcsBlob for all providers, and further, should we enhance it to use the asynchronous gcloud-aio-storage client to simplify our implementation?
Decision Drivers
- Minimize latency from GCS updates to Merino data availability.
- Minimize performance overhead by frequent metadata checks (not full blob).
- Simplify maintenance with a consistent solution.
- Continue to avoid blocking Merino's async event loop (ADR 0005).
Considered Options
| Option | Summary | Pros | Cons | |
|---|---|---|---|---|
| A | SyncedGcsBlob + gcloud-aio-storage (preferred) | Adopt async GCS client within SyncedGcsBlob | Low latency, minimal memory usage, non-blocking I/O, consistent implementation | Requires refactor |
| B | SyncedGcsBlob with current sync GCS client | Use existing SyncedGcsBlob (status quo) | Low latency, existing solution | Memory overhead from threads |
| C | Provider-specific loaders | Keep per-provider loading logic | No immediate refactor, flexible per provider | Duplicate logic, higher maintenance |
| D | GCS → Pub/Sub push | Event-driven notifications | Instant updates | Increased complexity, more infrastructure |
Recommended Option
- Option A: Adopt
SyncedGcsBlobenhanced withgcloud-aio-storage.
This approach efficiently reduces latency, simplifies asynchronous handling by removing the thread-pool complexity in the current implementation of SyncedGcsBlob, and maintains the decision outcome of ADR-0005.
By integrating gcloud-aio-storage into SyncedGcsBlob, it will natively use asynchronous I/O, and stop offloading synchronous calls to threads.
Positive Consequences
- Minimal latency: Rapid propagation of GCS updates.
- Low memory overhead: Leveraging async avoids creating a separate thread for each job.
- Low network overhead: Frequent metadata checks instead of full downloads.
- Maintenance ease: Standard implementation across providers.
Negative Consequences
- Initial refactor: Existing providers require updating.
Implementation Impact
Adopting this approach will require the following changes:
- SyncedGcsBlob - Refactor to use the async
gcloud-aio-storageclient instead of the synchronous client - TopPicks - Replace periodic reload with
SyncedGcsBlobto check for updates - Manifest - Replace periodic reload with
SyncedGcsBlobto check for updates
Curated Recommendations already uses SyncedGcsBlob and will benefit from the async refactor without requiring significant changes.
Usage Example
Here's how providers will initialize and use the enhanced asynchronous SyncedGcsBlob:
async def initialize_provider_backend() -> ProviderBackend:
try:
storage_client = AsyncStorageClient(...) # from gcloud-aio-storage
synced_blob = SyncedGcsBlob(
storage_client=storage_client,
metrics_client=get_metrics_client(),
metrics_namespace="provider.data",
bucket_name=settings.provider.gcs.bucket_name,
blob_name=settings.provider.gcs.data.blob_name,
max_size=settings.provider.gcs.data.max_size,
cron_interval_seconds=settings.provider.gcs.data.cron_interval_seconds, # How often 'updated' timestamp is checked
cron_job_name="fetch_provider_data",
)
synced_blob.set_fetch_callback(parse_and_cache_provider_data)
await synced_blob.initialize() # starts async background task
return GcsProviderBackend(synced_gcs_blob=synced_blob)
except Exception as e:
logger.error(f"Failed to initialize provider backend: {e}")
return DefaultProviderBackend()
def parse_and_cache_provider_data(data: str) -> None:
provider_data = json.loads(data)
cache_provider_data(provider_data)
The callback (parse_and_cache_provider_data) is called automatically by SyncedGcsBlob whenever the blob is updated. The callback implementation will vary; typical it decodes JSON, sometimes converting it to Pydantic models, and caching in memory.
Links
Extend Merino via Rust Extensions
- Status: Proposed
- Deciders: All Merino engineers
- Date: 2025-07-28
Context and Problem Statement
As Merino continues to expand with an ever-growing user base, performance hot-spots and resource intensive code paths have emerged in the code base, which impose new challenges in service scalability and operational cost hikes.
As a common solution, Python extensions can be developed for performance critical modules, but they also bring their own challenges such as the familiarity with a low-level language (e.g. C/C++ or Rust), tooling, and the potential issues (e.g. memory safety).
In this ADR, we explore various options to develop Python extensions for Merino and aim to identify a reasonable approach for us extend Merino to meet the performance needs while maintaining the overall developer experience that we equally value for the project.
Note that:
Instead of re-writing performance critical parts as language-level extensions, we could also carve certain functionalities out and tackle them separately outside of Merino. For instance, a new service can be added to handle a computationally intensive task for Merino. Or a dedicated external storage system can be used to replace an in-memory dataset in Merino.
That approach is out of scope for this ADR as it normally requires a wider discussion on service architecture or system design changes. This ADR only focuses on extensions on the language level.
Decision Drivers
- The ability to meet the desirable performance requirements and to get fine-grained control over compute resources.
- Developer experience. Developing Merino extensions should not have negative impact on the overall developer experience of Merino.
- System safety. Performance boost should not be achieved at the cost of system safety regressions.
Considered Options
- A. Extend Merino via Rust extensions through PyO3/Maturin ecosystem.
- B. Extend Merino via C/C++ extensions.
- C. Maintain status quo – build Merino in pure Python.
Decision Outcome
Chosen option:
- A. "Extend Merino via Rust extensions through PyO3/Maturin ecosystem".
Positive Consequences
- Rust is a system programming language suitable for developing performance critical software. PyO3/Maturin is a mature ecosystem for building Python extensions.
- Rust has been widely adopted at Mozilla for both server and client side development. Its learning curve is relatively lower than other counterparts such as C/C++ for Python extension development.
- Rust's strong memory safety guarantees are superior than other competitors.
Negative Consequence
- Rust would be a requirement for Merino's extension development, which comes with its own learning curve.
- Require the familiarity with PyO3/Maturin.
Mitigations
- To minimize interruptions, Merino extensions will be developed as a separate Python package using a dedicated git repo. The extensions will be added to Merino as a PyI dependence. For Merino developers who do not work on extensions, their development experience will remain unchanged.
- While the basic familiarity with PyO3/Maturin is still required for Merino extension
developers, common development actions can be provided via
uvand Makefile tasks. Package building and publishing will be automated in CI. - The DISCO team will host "Office Hours" regularly to help Merino developers with questions about Rust & extension development.
Pros and Cons of the Options
Option A: Extend Merino via Rust extensions Through PyO3/Maturin
This approach allows Merino developers to identify the performance critical code in Merino and re-implement it as Python extensions in Rust via PyO3 to boost system performance or resolve bottlenecks.
Pros
- Using Python extensions is a common way to achieve higher performance and lower resource footprint in Python.
- Rust has gained its popularity in building Python extensions lately. Many popular
Python extensions, including the ones used by Merino, e.g.
pydanticandorjson, are built in Rust via Pyo3. - Building Python extensions normally requires manual management of compute resources using a low-level language, hence extensions are prone to memory safety bugs. Rust is superior over its competitors w.r.t avoiding memory safety issues as it is a memory safe language.
Cons
- Rust has a steep learning curve.
- Many disruptive changes from build, test, and release to Merino's development processes if we were to introduce Rust and PyO3 to the Merino project, which could negatively affect Merino's developer experience especially for folks that do not work on extensions.
Option B: Extend Merino via C/C++ Extensions
C/C++ and Cython are the most popular languages for developing Python extension development. While being the most mature solution, it requires the use of C/C++ that is even more alien than Rust to most Merino developers.
Pros
- The most mature ecosystem as it's the standard way to build Python extensions.
- Best performance.
Cons
- C/C++ has an equally steep learning curve as Rust.
- C/C++ is memory unsafe and more likely to introduce safety issues to Merino.
Option C: Maintain Status Quo – Build Merino in pure Python
We could continue to build everything in Python for Merino. For performance critical code, we could either optimize it in pure Python or resort to third party packages if any.
Pros
- Python is all we need for Merino development.
- No changes required for build, package, and release processes.
Cons
- Could be difficult to optimize things if bare-metal or fine-grained resource control is needed.
- Of-the-shelf solutions are not always available specifically for business logic code paths.
Dedicated Weather Endpoint to Serve New Tab Weather Widget Requests
- Status: Approved
- Deciders: DISCO, Home & New Tab, Search & Suggest teams
- Date: 2026-02-06
Technical Story: Serve New Tab Weather Widget requests from a dedicated endpoint instead of v1/suggest to reduce coupling and allow widget-specific caching/TTL and roadmap expansion (hourly forecasts, alerts).
Context and Problem Statement
The v1/suggest endpoint was originally designed for Firefox search bar suggestions, but has expanded over time to serve multiple provider-backed experiences (weather, stocks, flights, sports, etc.). The New Tab Weather Widget has different product requirements (including a roadmap for hourly forecasts and alerts), different request volume and frequency patterns, and different caching/TTL needs than the search bar suggestions. Additionally, the weather widget on the new tab uses the same code as search and suggest to request weather data.
How should we separate New Tab Weather Widget weather requests from v1/suggest to reduce coupling, improve flexibility (features and caching), and keep client engineering simple?
Decision Drivers
-
Caching / TTL control -- Curcial Requirement
Allow weather-specific cache TTLs aligned with HTTP response caching headers. This will allow us to control the number of live requests made to the Accuweather API to manage the monthly quota. This is very important to keep the costs down since we plan to introduce this widget in new regions which means the total number of requests will increase. -
Decouple client needs
Search bar and new tab have different behaviors, performance expectations, and product needs. -
Future extensibility
Support hourly forecasts, alerts, and other weather expansions without growingv1/suggestfurther. -
Client simplicity
Keep client integration straightforward and stable. -
Operational clarity
Clearer ownership, metrics, and planning per endpoint and client. -
Backward compatibility
Avoid breaking existing search bar consumers and provider integrations. -
Level of effort in separating HTTP traffic (for weather) from OHTTP (for suggest) in Merino Splitting traffic based on HTTP and OHTTP requests will be simpler and weather functionality relies on HTTP.
Considered Options
- A. Keep using
v1/suggestfor weather (status quo), continue adding weather capabilities there. - B. Create resource-oriented endpoints under
v1/weather/*
(e.g.,v1/weather/weather-report,v1/weather/hourly-forecasts,v1/weather/alerts). - C. Create a single
v1/weatherendpoint with query-driven expansions
(e.g.,v1/weather?include=hourly,alerts) while returning the base report by default. - D. Create a dedicated product-scoped endpoint
(e.g.,v1/newtab/weather) explicitly tied to the New Tab experience.
Pros and Cons of each option
A. Keep weather in v1/suggest
Pros
- No client migration required.
- Avoids introducing new endpoints or contracts in the short term.
Cons
- Continues tight coupling between search bar and new tab requirements.
- Difficult to apply widget-specific caching/TTL and HTTP headers without impacting search bar behavior.
v1/suggestcontinues to grow in scope and operational complexity.- Serving HTTP requests will be very difficult since the
v1/suggestendpoint will be used for OHTTP requests going forward.
B. Multiple new endpoints under v1/weather/* (Recommended based on the crucial requirement above)
Pros
- Clear separation of concerns by resource and capability (Better alignment with REST/resource-oriented design).
- Explicit and independent caching semantics per endpoint (e.g., hourly vs alerts).
- Simpler server-side logic: Handlers don’t need branching logic based on include= flags. Each endpoint can be implemented, tested, and optimized independently.
- Response payload shape does not depend on
Suggestiontype.
Cons
- Client will have to make more than one request depending on the weather data required.
- Clients will have to migrate over to the new endpoints. Requests could be made to different endpoints i.e
v1/suggestandv1/weatherbased on the data needed. - More client complexity: The client has to coordinate parallel fetches, retries, partial failures (e.g., report succeeds but alerts fail), and loading states.
- More endpoints to document, monitor, version, and operate.
C. Single v1/weather endpoint with include= expansions
Pros
- Simple client integration: base report by default, opt-in expansions as needed.
- One request can serve the widget UI while still allowing selective feature growth.
- Keeps endpoint surface area small while remaining extensible.
Cons
- Behaviour is somewhat similar to the existing
v1/suggestbehaviour. - Cannot use different cache-control headers for different types of data. Have to use a minimum TTL to represent all types of data in the response.
- More complex server-side logic for assembling partial responses and setting appropriate headers.
D. Product-scoped endpoint (v1/newtab/weather)
Pros
- Very clear ownership and intent: explicitly tied to the New Tab Weather Widget.
- Maximum freedom to optimize behavior and performance for widget-specific needs.
Cons
- Risk of duplicating weather-domain APIs across products over time.
- Feels like a bit of an overkill at this point.
- Implies that only new tab can access this endpoint and can cause confusion among different clients in the future.
- May lead to API fragmentation if other products follow the same pattern.
Additional Suggestions and Recommendations
Option B Seems like the best option for the problems we are trying to solve right now. It allows us flexibility with cache TTLs, simpler logic and implementation without having to do query/request param parsing. It also allows us to grow the weather functionality with different types weather data easily, without creating more coupling with the v1/suggest endpoint.
Implementation Plan
- Keep
v1/suggestbehavior stable. i.e it will serve the current weather report suggestion response (used by search bar and current weather widget). - Create a new endpoint
v1/weather/hourly-forecaststo serve hourly forecasts first. - Eventually add functionality to serve the existing weather report and location completions via
v1/weather/*. This will allow all weather data consumers to move off of using the search and suggest code. That will allow us to deprecate theaccuweatherprovider for thev1/suggestendpoint. - Expand functionality for new weather features (e.g alerts) under the new endpoint.
Adopt Monorepo for Merino
- Status: Accepted
- Deciders: Merino devs
- Date: 2026-05-01
Context and Problem Statement
As Firefox Suggest and New Tab page continue to grow, new features and functionalities need to be built for Merino. In addition, there is a need in building new applications to work alongside with Merino to support the products. How can we find the optimal way to manage all those code artifacts? Shall we opt for monorepo or polyrepos?
Decision Drivers
- Developer experience.
- Operational complexity.
Considered Options
- A. Monorepo
- B. Polyrepos
Decision Outcome
Propsed option:
- A. Monorepo
The monorepo approach allows Merino developers to manage related function units (e.g. libraries and application) in the same repo, which not only eases the cognitive burden for developers when working , but also simplifies code reuse and dependency management. Tools such as uv can be used to assist the monorepo management and mitigate the overhead with monorepo.
The following can be adopted for Merino developers to mitigate various downsides with monorepo:
- We can adopt a stricter "component" approach for code structuring and divisions. Workspace members (i.e. components) should have clear responsbilities and boundraries.
- Naming and structure conventions can be used to accelerate testing and maintain the developer experience.
- To mitigate the immaturity of the tooling on dependency management, we can establish dependency update guidelines for all workspace packages.
Pros and Cons of the Options
Monorepo
Monorepo allows us to use a single git repo to home all the code artifacts, including dependencies, packages for both common libraries and applications, and other shared resources such as linting and CI/CD settings. To facilitate that, we can reshape the existing Merino repo into a workspace and use workspace members to manage individual packages including shared libraries and independent applications. Thankfully, uv has built-in support for workspace management.
Pros
- Low cognitive load: Relevant code artifacts are co-located in the same repo.
- Easy code reuse and sharing: Shared libraries and components can be used across the repo.
- Simplified dependencies management: All repo memebers share the same dependencies. Unused dependencies are easier to be identified and removed.
- Better coding consistency: The same linting and styling rules will be enforced for all repo members.
- Simpler change control: Smaller blast radius of code changes. Breaking changes can be made in one repo within one PR.
- Simplified end-to-end testing: Related services can be run and tested within the same repo.
Cons
- More involved package management: Compared to a single package repo, a monorepo with multiple members will require more sophisticated tooling and settings across the board.
- Workflow performance issues: As the repo grows, performance issues could emerge in local development (e.g. excessive testing time), Git operations, CI/CD (e.g. slow build and deploys).
- Extra effort in design and maintenance. Collective discipline and careful design are required to keep the workspace members well-structured and maintainable.
- Tooling maturity. Certain features are still missing in
uvon workspace management. For instance, it does not support sharing dependencies across workspace members. Will have to work around those with sub-optimal alternatives.
Polyrepos
As opposed to monorepo, polyrepos use multiple repos to manage individual functional components, respectively. Each of them would has its own packages, tests, dependencies, and CI/CD settings. They can be either used as a dependent package (once published to a registry) by other projects or run as an application itself. This is Merino's current repo strcuture, for instance, the Merino extension is managed in its own repo and published to PyPI (moz-merino-ext) so that Merino can use it.
Pros
- Smaller codebases with clear boundary: Each repo only cares one concern.
- Autonomy: The choices of tooling, dependencies, styling, workflows are up to the repo owners.
- Smooth workflow: The build-test-deploy workflow is more straightforward and performance than that of monorepo.
Cons
- High cognitive load, particularly with multiple highly contextual and inter-dependent repos.
- The risk of "Dependency Hell": Each repo manages its own dependencies, extra effort is needed to avoid dependencies conflicts.
- Duplication: Code duplication and common tasks such as linting and CI/CD settings need to be written and configured for every repo.
- Harder to maintain consistency: Each repo could develop its own conventions and bespoke workflows that are harmful for maintainability and cross-functional collaboration.