Merino
A service to provide address bar suggestions to Firefox. Some of this content comes from third parties. In this case, Merino serves as a privacy preserving buffer.
About the Name
This project drives an important part of Firefox's "felt experience". That is, the feeling of using Firefox, hopefully in a delightful way. The word "felt" in this phrase refers to feeling, but it can be punned to refer to the textile. Felt is often made of wool, and Merino wool (from Merino sheep) produces exceptionally smooth felt.
Merino API documentation
This page describes the API endpoints available on Merino.
Suggest
Endpoint: /api/v1/suggest
Example: /api/v1/suggest?q=nelson%20mand&client_variants=one,two
The primary endpoint for the browser to consume, this endpoint consumes user input and suggests pages the user may want to visit. The expectation is that this is shown alongside other content the browser suggests to the user, such as bookmarks and history.
This endpoint accepts GET requests and takes parameters as query string values and headers.
Query Parameters
-
q- The query that the user has typed. This is expected to be a partial input, sent as fast as once per keystroke, though a slower period may be appropriate for the user agent. -
client_variants- Optional. A comma-separated list of any experiments or rollouts that are affecting the client's Suggest experience. If Merino recognizes any of them it will modify its behavior accordingly. -
providers- Optional. A comma-separated list of providers to use for this request. See the/providersendpoint below for valid options. If provided, only suggestions from the listed providers will be returned. If not provided, Merino will use a built-in default set of providers. The default set of providers can be seen in the/providersendpoint.
Headers
-
Accept-Language- The locale preferences expressed in this header in accordance with RFC 2616 section 14.4 will be used to determine suggestions. Merino maintains a list of supported locales. Merino will choose the locale from it's list that has the highestq(quality) value in the user'sAccept-Languageheader. Locales withq=0will not be used.If no locales match, Merino will not return any suggestions. If the header is not included or empty, Merino will default to the
en-USlocale.If the highest quality, compatible language produces no suggestion results, Merino will return an empty list instead of attempting to query other languages.
-
User-Agent- A user's device form factor, operating system, and browser/Firefox version are detected from theUser-Agentheader included in the request.
Other derived inputs
-
Location - The IP address of the user or nearest proxy will be used to determine location. This location may be as granular as city level, depending on server configuration.
Users that use VPN services will be identified according to the VPN exit node they use, allowing them to change Merino's understanding of their location. VPN exit nodes are often mis-identified in geolocation databases, and may produce unreliable results.
Response
Response object
The response will be a JSON object containing the following keys:
client_variants- A list of strings specified from theclient_variantsparameter in the request.server_variants- A list of strings indicating the server variants.request_id- A string identifier identifying every API request sent from Firefox.suggestions- A list of suggestion objects described as below.
Suggestion object
-
block_id- a number that can be used, along with theproviderfield below, to uniquely identify this suggestion. Two suggestions with the sameproviderandblock_idshould be treated as the same suggestion, even if other fields, such asclick_urlchange. Merino will enforce that they are equivalent from a user's point of view. -
full_keyword- In the case that the query was a partial match to the suggestion, this is the completed query that would also match this query. For example, if the user was searching for fruit and typed "appl", this field might contain the string "apples". This is suitable to show as a completion of the user's input. This field should be treated as plain text. -
title- The full title of the suggestion resulting from the query. Using the example of apples above, this might be "Types of Apples in the Pacific Northwest". This field should be treated as plain text. -
url- The URL of the page that should be navigated to if the user selects this suggestion. This will be a resource with the title specified in thetitlefield. -
impression_url- A provider specified telemetry URL that should be notified if the browser shows this suggestion to the user. This is used along withclick_urlto monitor the relevancy of suggestions. For more details see Interaction Pings, below. This field may be null, in which case no impression ping is required for this suggestion provider. -
click_url- A provider specified telemetry URL that should be notified if the user selects this suggestion. This should only be notified as the result of positive user action, and only if the user has navigated to the page specified in theurlfield. For more details see Interaction Pings, below. This field may be null, in which case no click ping is required for this suggestion provider. -
provider- A string that identifies the provider of this suggestion, such as "adM". In general, this field is not intended to be directly displayed to the user. -
advertiser- The name of the advertiser, such as "Nike". Note that aprovidercould have multipleadvertisers. -
is_sponsored- A boolean indicating if this suggestion is sponsored content. If this is true, the UI must indicate to the user that the suggestion is sponsored. -
icon- A URL of an image to display alongside the suggestion. This will be a small square image, suitable to be included inline with the text, such as a site's favicon. -
score- A value between 0.0 and 1.0 used to compare suggestions. When choosing a suggestion to show the user, higher scored suggestions are preferred.
Response Headers
Responses will carry standard HTTP caching headers that indicate the validity of the suggestions. User agents should prefer to provide the user with cached results as indicated by these headers.
Response Status Codes
- 200 OK - Suggestions provided normally.
- 4xx - Client error. See response for details.
- 5xx - Internal server error. Try again later.
Interaction Pings
When a Firefox user views or selects a suggestion from Merino, Firefox will send
an impression or a click ping to a Mozilla-controlled service indicating this
user interaction. Some suggestion providers may also need that interaction data
for reporting and relevancy optimization. Firefox will not send the pings to
those providers directly, rather, it will delegate those to a Mozilla-controlled
service, by which the interaction pings will be sent to the impression_url or
click_url specified by the providers.
If the URL for an interaction ping is not specified (for example, click_url is
null), then no ping should be sent to the provider for that action. However,
this interaction ping is always sent to the Mozilla-controlled service unless
the user opts out the telemetry collection of Firefox.
The required behavior for interaction pings is TBD.
Providers
Endpoint: /api/v1/providers
This endpoint gives a list of available providers, along with their availability. It accepts GET requests and takes no parameters.
Response
The response will be a JSON object containing the key providers, which is a
map where the keys to this map are the IDs of the provider, and the values are
provider metadata object. Each provider metadata object will have the following
format:
-
id- A string that can be used to identify this provider. This ID can be used for theprovidersfield of the suggest API. -
availability- A string describing how this provider is used in Merino. It will be one of:"enabled_by_default"- This provider will be used for requests that don't specify providers, and it should be provided to the user as a selection that can be turned off."disabled_by_default"- This provider is not used automatically. It should be provided to the user as a selection that could be turned on."hidden"- This provider is not used automatically. It should not be provided to the user as an option to turn on. It may be used for debugging or other internal uses. */
Configuring Firefox and Merino Environments
As of Firefox 93.0, Merino is not enabled by default. To enable it, set the
Firefox preference browser.urlbar.merino.enabled to true. By default Merino
will connect to the production environments. This is controlled with the
browser.urlbar.merino.endpointURL preference. See below for other options.
You can also query any of the endpoint URLs below with something like
curl 'https://stage.merino.nonprod.cloudops.mozgcp.net/api/v1/suggest?q=your query'
Environments
Production
Endpoint URL: https://merino.services.mozilla.com/api/v1/suggest
The primary environment for end users. Firefox is configured to use this by default. As of 2021-10-25, this server is not active yet.
This environment only deploys manually as a result of operations triggering deploys.
Stage
Endpoint URL: https://stage.merino.nonprod.cloudops.mozgcp.net/api/v1/suggest
This environment is used for manual and load testing of the server. It is not guaranteed to be stable or available. It is used as a part of the deploy process to verify new releases before they got to production.
This environment automatically deploys new tags on the Merino repository.
Dev
Endpoint URL: https://dev.merino.nonprod.cloudops.mozgcp.net/api/v1/suggest
This environment is unstable and is not guaranteed to work. It's primary use is as a development area for operations.
This environment automatically deploys the latest commit to the main branch of
the repository.
Configuring Merino (Operations)
Settings
Merino's settings can be specified in two ways: a YAML file placed in a specific location, or via environment variables. Not all settings can be set with environment variables, however. Notably, provider configuration must be done with its own YAML file.
File organization
These are the settings sources, with later sources overriding earlier ones.
-
A base configuration checked into the repository, in
config/base.yaml. This provides the default values for most settings. -
Per-environment configuration files in the
configdirectory. The environment is selected using the environment variableMERINO__ENV. The settings for that environment are then loaded fromconfig/${env}.yaml, if it exists. The default environment is "development". A "production" environment is also provided. -
A local configuration file not checked into the repository, at
config/local.yaml. This file is in.gitignoreand is safe to use for local configuration and secrets if desired. -
Environment variables that begin with
MERINOand use__(a double underscore) as a level separator. For example,Settings::http::workerscan be controlled from the environment variableMERINO__HTTP__WORKERS.
The names given below are of the form "yaml.path (ENVIRONMENT_VAR)"
General
-
env(MERINO__ENV) - Only settable from environment variables. Controls which environment configuration is loaded, as described above. -
debug(MERINO__DEBUG) - Boolean that enables additional features to debug the application. This should not be set to true in public environments, as it reveals all configuration, including any configured secrets. -
public_documentation(MERINO__PUBLIC_DOCUMENTATION) - When users visit the root of the server, they will be redirected to this URL. Preferable a public wiki page that explains what the server is and does. -
log_full_request(MERINO__LOG_FULL_REQUEST) - Boolean that enables logging the entire suggestion request object as a part of the tracing log, including the search query. When the setting is false (default), the suggest request object should be logged, but the search query should be blank. Note that access to the collected query logs is restricted.
HTTP
Settings for the HTTP server.
http.listen(MERINO__HTTP__LISTEN) - An IP and port to listen on, such as127.0.0.1:8080or0.0.0.0:80.http.workers(MERINO__HTTP__WORKERS) - Optional. The number of worker threads that should be spawned to handle tasks. If not provided will default to the number of logical CPU cores available.
Logging
Settings to control the format and amount of logs generated.
-
logging.format- The format to emit logs in. One ofpretty(default in development) - Multiple lines per event, human-oriented formatting and color.compact- A single line per event, with formatting and colors.mozlog(default in production) - A single line per event, formatted as JSON in MozLog format.
-
logging.info(MERINO__LOGGING__LEVELS) - Minimum level of logs that should be reported. This should be a number of entries separated by commas (for environment variables) or specified as list (YAML).This will be combined with the contents of the
RUST_LOGenvironment variable for compatibility.RUST_LOGwill take precedence over this setting. If the environment variableMERINO__LOGGING__LEVELSis specified, all the settings in the YAML file will be ignored.Each entry can be one of
ERROR,WARN,INFO,DEBUG, orTRACE(in increasing verbosity), with an optional component that specifies the source of the logs. For exampleINFO,merino_web=DEBUG,reqwest=WARNwould set the default log level to INFO, but would lower the level toDEBUGfor themerino-webcrate and raise it toWARNfor the reqwest crate.
Metrics
Settings for Statsd/Datadog style metrics reporting.
-
metrics.sink_host(MERINO__METRICS__SINK_ADDRESS) - The IP or hostname to send metrics to over UDP. Defaults to0.0.0.0. -
metrics.sink_port(MERINO__METRICS__SINK_PORT) - The port to send metrics to over UDP. Defaults to 8125. -
max_queue_size_kb(MERINO__METRICS__MAX_QUEUE_SIZE_KB) - The maximum size of the buffer that holds events waiting to be sent. If unsent events rise above this, then metrics will be lost. Defaults to 32KB.
Sentry
Error reporting via Sentry.
sentry.mode(MERINO__SENTRY__MODE) - The type of Sentry integration to enable. One ofrelease,server_debug,local_debug, ordisabled. The twodebugsettings should only be used for local development.
If sentry.mode is set to release, then the following two settings are
required:
sentry.dsn- Configuration to connect to the Sentry project.sentry.env- The environment to report to Sentry. Probably "production", "stage", or "dev".
If sentry.mode is set to disabled, no Sentry integration will be activated.
If it is set to local_debug, the DSN will be set to a testing value
recommended by Sentry, and extra output will be included in the logs.
The mode can be set to server_debug, which will allow testing real integration
with Sentry. Sentry integration and debug logging will be activated. It is
recommended to use the merino-local sentry environment.
See that page for DSN information. The following two settings are required:
sentry.dsn- Configuration to connect to the Sentry project. A testing project should be used.sentry.who- Your username, which will be used as the environment, so that you can filter your results out in Sentry's web interface.
Redis
Connection to Redis. This is used by the Redis provider cache below.
redis.url(MERINO__REDIS__URL) - The URL to connect Redis at. Example:redis://127.0.0.1/0.
Remote_settings
Connection to Remote Settings. This is used by the Remote Settings suggestion provider below.
-
remote_settings.server(MERINO__REMOTE_SETTINGS__SERVER) - The server to sync from. Example:https://firefox.settings.services.mozilla.com. -
remote_settings.default_bucket(MERINO__REMOTE_SETTINGS__DEFAULT_BUCKET) - The bucket to use for Remote Settings providers if not specified in the provider config. Example: "main". -
remote_settings.default_collection(MERINO__REMOTE_SETTINGS__DEFAULT_COLLECTION) - The collection to use for Remote Settings providers if not specified in the provider config. Example: "quicksuggest". -
remote_settings.cron_interval_sec(MERINO__REMOTE_SETTINGS__CRON_INTERVAL_SEC) - The interval of the Remote Settings cron job (in seconds). Following tasks are done in this cron job:- Resync with Remote Settings if needed. The resync interval is configured
separately by the provider. Note that this interval should be set smaller
than
resync_interval_secof the Remote Settings leaf provider. - Retry if the regular resync fails.
- Resync with Remote Settings if needed. The resync interval is configured
separately by the provider. Note that this interval should be set smaller
than
-
remote_settings.http_timeout_sec(MERINO__REMOTE_SETTINGS__HTTP_TIMEOUT_SEC) - The HTTP timeout (in seconds) for the underlying HTTP client of the Remote Settings client.
Location
Configuration for determining the location of users.
location.maxmind_database(MERINO__LOCATION__MAXMIND_DATABASE) - Path to a MaxMind GeoIP database file. Optional. If not specified, geolocation will be disabled.
Provider Configuration
The configuration for suggestion providers.
Note that the provider settings are configured either by a separate YAML file
located in config/providers or by a remote source backed by an HTTP endpoint.
You can use provider_settings to configure how & where Merino to load the
settings.
Provider Settings
You can specify the "type" and the "location" of the provider settings. The
"type" could be local or remote. For local sources, use path to specify
the location; Use uri for remote sources. Note that only JSON is supported
for remote sources, whereas all the common formats (JSON, YAML, TOML, etc) are
supported for local sources.
Examples:
- A local source
provider_settings:
type: local
path: ./config/providers/base.yaml
- A remote source
provider_settings:
type: remote
uri: https://example.org/settings
Configuration Object
Each provider configuration has a type, listed below, and it's own individual
settings.
Example:
wiki_fruit:
type: wiki_fruit
Configuration File
Each configuration file should be a map where the keys are provider IDs will be used in the API to enable and disable providers per request. The values are provider configuration objects, detailed below. Some providers can takes other providers as children. Because of this, each key in this config is referred to as a "provider tree".
Example:
adm:
type: memory_cache
inner:
type: remote_settings
collection: "quicksuggest"
wiki_fruit:
type: wiki_fruit
debug:
type: debug
Leaf Providers
These are production providers that generate suggestions.
- Remote Settings - Provides suggestions from a RS collection, such as the
suggestions provided by adM. See also the top level configuration for Remote
Settings, below.
type=remote_settingsbucket- Optional. The name of the Remote Settings collection to pull suggestions from. If not specified, the global default will be used.collection- Optional. The name of the Remote Settings collection to pull suggestions from. If not specifeid, the global default will be used.resync_interval_sec- Optional. The time between re-syncs of Remote Settings data, in seconds. Defaults to 3 hours.
Combinators
These are providers that extend, combine, or otherwise modify other providers.
-
Multiplexer - Combines providers from multiple sub-providers.
type=multiplexerproviders- A list of other provider configs to draw suggestions from.
Example:
sample_multi: type: multiplexer providers: - fixed: type: fixed value: I'm a banana - debug: type: debug -
Timeout - Returns an empty response if the wrapped provider takes too long to respond.
type=timeoutinner- Another provider configuration to generate suggestions with.max_time_ms- The time, in milliseconds, that a provider has to respond before an empty result is returned.
-
KeywordFilter - Filters the suggestions coming from the wrapped provider with the given blocklist.
type=keyword_filtersuggestion_blocklist- The map used to define the blocklist rules. Each entry contains a rule id and an associated regular expression that recommended titles are matched against.inner- The wrapped provider to draw suggestions from.
Example:
filtered: type: keyword_filter suggestion_blocklist: no_banana: "(Banana|banana|plant)" inner: type: multiplexer providers: - fixed: type: fixed value: I'm a banana - debug: type: debug -
ClientVariantSwitch - Switches between two providers based on whether a request's client variants matches the configured client variant string
type=client_variant_switchclient_variant- the string used to determine whether the matching or default provider is usedmatching_provider- The wrapped provider to draw suggestions from for a client variant match.default_provider- The wrapped provider to draw suggestions when there is not a client variant match.
Example:
client_variant_switch: type: client_variant_switch client_variant: "hello" matching_provider: type: wiki_fruit default_provider: type: debug -
Stealth - Runs another provider, but hides the results. Useful for load testing of new behavior.
type=stealthinner- Another provider configuration to run.
Caches
These providers take suggestions from their children and cache them for future use.
-
Memory Cache - An in-memory, per process cache.
type=memory_cachedefault_ttl_sec- The time to store suggestions before, if the inner provider does not specify a time.cleanup_interval_sec- The cache will automatically remove expired entries with this period. Note that expired entries are also removed dynamically if a matching request is processed.max_removed_entries- While running the cleanup task, at most this many entries will be removed before cancelling the task. This should be used to limit the maximum amount of time the cleanup task takes. Defaults to 100_000.default_lock_timeout_sec- The amount of time a cache entry can be locked for writing.inner- Another provider configuration to generate suggestions with.
-
Redis Cache - A remote cache that can be shared between processes.
type=redis_cachedefault_ttl_sec- The time to store suggestions before, if the inner provider does not specify a time.default_lock_timeout_sec- The amount of time a cache entry can be locked for writing.inner- Another provider configuration to generate suggestions with.
Development providers
These should not be used in production, but are useful for development and testing.
-
Debug - Echos back the suggestion request that it receives formatted as JSON in the
titlefield of a suggestion.type=debug
-
WikiFruit - A very basic provider that suggests Wikipedia articles for the exact phrases "apple", "banana", and "cherry".
type=wiki_fruit
-
Null - A provider that never suggests anything. Useful to fill in combinators and caches for testing.
type="null"- Note thatnullin YAML is an actual null value, so this must be specified as the string"null".
-
Fixed - A suggestion provider that provides a fixed response with a customizable title.
value- A string that will be used for the title of the fixed suggestion. Required.
Data collection
This page should list all metrics and logs that Merino is expected to emit in production, including what should be done about them, if anything.
Logs
This list does not include any DEBUG or TRACE level events, since those are
not logged by default in production. The events below are grouped by crate, and
the level and type of the log is listed.
Any log containing sensitive data must include a boolean field sensitive
that is set to true to exempt it from flowing to the generally accessible
log inspection interfaces.
cache.memory.remove-expired- A record of expired entries for tracing framework for structured logging an diagnostics. Logs duration, removed pointers, and removed storage.
merino-adm
-
INFO adm.remote-settings.sync-start- The Remote Settings provider has started syncing records. -
WARN adm.remote-settings.empty- After syncing no records were found in the Remote Settings collection.
merino-cache
INFO cache.redis.save-error- There was an error while saving a cached suggestion to the Redis server.
merino-web
-
INFO web.suggest.request- A suggestion request is being processed. This event will include fields for all relevant details of the request. Fields:sensitive- Always set to true to ensure proper routing.query- If query logging is enabled, the text the user typed. Otherwise an empty string.country- The country the request came from.region- The first country subdivision the request came from.city- The city the request came from.dma- A US-only location description that is larger than city and smaller than states, but does not align to political borders.agent- The original user agent.os_family- Parsed from the user agent. One of "windows", "macos", "linux", "ios", "android", "chrome os", "blackberry", or "other".form_factor- Parsed from the user agent. One of "desktop", "phone", "tablet", or "other"browser- The browser and possibly version detected. Either "Firefox(XX)" where XX is the version, or "Other".rid- The request ID.accepts_english- True if the user's Accept-Language header includes an English locale, false otherwise.requested_providers- A comma separated list of providers requested via the query string, or an empty string if none were requested (in which case the default values would be used).client_variants- Any client variants sent to Merino in the query string.session_id- A UUID generated by the client for each search session.sequence_no- A client-side event counter (0-based) that records the query sequence within each search session.
-
INFO web.configuring-suggesters- A web worker is starting to configure local suggesters, which may take some seconds and require network traffic to synchronize data. -
ERROR web.suggest.setup-error- There was an error while setting up configuration providers. This may be temporary, and future requests will attempt to configure providers again. -
ERROR web.suggest.error- There was an error while providing suggestions from an otherwise set-up provider. This may represent a network or configuration error. -
ERROR dockerflow.error_endpoint- The__error__endpoint of the server was called. This is used to test our error reporting system. It is not a cause for concern, unless we receive a large amount of these records, in which case some outside service is likely malicious or misconfigured.
Metrics
A note on timers: Statsd timers are measured in milliseconds, and are reported as integers (at least in Cadence). Milliseconds are often not precise enough for the tasks we want to measure in Merino. Instead we use generic histograms to record microsecond times. Metrics recorded in this way should have
-usappended to their name, to mark the units used (since we shouldn't put the proper unit μs in metric names).
-
startup- A counter incremented at startup, right after metrics are initialized, to signal a successful metrics system initialization. -
client_variants.<variant_name>- A counter incremented for each client variant present in a query request, incremented when the response is assembled with the suggestions. -
request.suggestion-per- A histogram that reports the number of suggestions in a response for a given query. -
keywordfilter.match- Report the number of suggestions filtered by the filter with the given ID.Tags:
id- The filter that was matched.
-
adm.rs.provider.duration-us- A histogram that records the amount of time, in microseconds, that the adM Remote Settings provider took to generate suggestions.Tags:
accepts-english- If the request included anAccept-Languageheader that accepted anyen-*locale. Only requests that do are provided with suggestions.
-
cache.memory.duration-us- A histogram that records the amount of time, in microseconds, that the memory cache took to provide a suggestion. Includes the time it takes to fallback to the inner provider for cache misses and errors.Tags:
cache-status- If the response was pulled from the cache or regenerated."hit","miss","error", or"none".
-
cache.memory.hit- A counter that is incremented every time the in-memory cache is queried and a cached suggestion is found. -
cache.memory.miss- A counter that is incremented every time the in-memory cache is queried and a cached suggestion is not found. -
cache.memory.pointers-len- A gauge representing the number of entries in the first level of hashing in the in-memory deduped hashmap. -
cache.memory.duration- A duration in milliseconds representing the time required for removal of expired entries. -
cache.memory.storage-len- A gauge representing the number of entries in the second level of hashing in the in-memory deduped hashmap. -
cache.redis.duration-us- A histogram that records the amount of time, in microseconds, that the Redis cache took to provide a suggestion. Includes the time it takes to fallback to the inner provider for cache misses and errors.Tags:
cache-status- If the response was pulled from the cache or regenerated."hit","miss","error", or"none".
-
cache.redis.hit- A counter that is incremented every time the redis cache is queried and a cached suggestion is found. -
cache.redis.miss- A counter that is incremented every time the redis cache is queried and a cached suggestion is not found.
Developer documentation for working on Merino
tl;dr
Here are some useful commands when working on Merino.
Run the main app
$ docker-compose -f dev/docker-compose.yaml up -d
$ cargo run -p merino
Run tests
$ docker-compose -f dev/docker-compose.yaml up -d
$ cargo test
Run dependency servers
$ cd dev
$ docker-compose up
Documentation
You can generate documentation, both code level and book level, for Merino and
all related crates by running ./dev/make-all-docs.sh. You'll need mdBook,
which you can get with cargo install mdbook.
Pre-built code docs are also available.
Local configuration
The default configuration of Merino is development, which has human-oriented
logging and debugging enabled. For settings that you wish to change in the
development configuration, you have two options, listed below.
For full details, make sure to check out the documentation for Merino's setting system.
Update the defaults
If the change you want to make makes the system better for most development
tasks, consider adding it to config/development.yaml, so that other developers
can take advantage of it. You can look at config/base.yaml, which defines all
requires configuration, to see an example of the structure.
It is not suitable to put secrets in config/development.yaml.
Create a local override
For local changes to adapt to your machine or tastes, you can put the
configuration in config/local.yaml. These file doesn't exist by default. These
changes won't be a part of the git history, so it is safe to put secrets here,
if needed. Importantly, it should never be required to have a local.yaml to
run Merino in a development setting.
Repository structure
This project is structured as a Cargo Workspace that contains one crate for each broad area of behavior for Merino. This structure is advantageous because the crates can be handled either individually or as a group. When compiling, each crate can be compiled in parallel, where dependencies allow, and when running tests, each test suite can be run separately or together. This also provides an advantage if we choose to re-use any of these crates in other projects, or if we publish the crates to Crates.io.
Project crates
This is a brief overview of the crates found in the repository. For more details, see the specific crate docs.
merino
This is the main Merino application, and one of the binary crates in the repository. It brings together and configures the other crates to create a production-like environment for Firefox Suggest.
merino-settings
This defines and documents the settings of the application. These settings should be initialized by one of the binary crates, and passed into the other crates to configure them.
merino-web
This crate provides an HTTP API to access Merino, including providing observability into the running of the application via that API.
merino-suggest
This is a domain crate that defines the data model and traits needed to provide suggestions to Firefox.
merino-cache
This crate contains domain models and behavior for Merino's caching functionality.
merino-adm
This crate provides integration with the AdMarketplace APIs, and implements the
traits from merino-suggest.
merino-showroom
This is not a Rust crate, but instead a small Javascript application. It can be used to test Merino during development and demos.
merino-integration-tests
This crate is a separate test system. It works much like merino, in that it
brings together the other crates to produce a complete Merino environment.
However, this binary crate produces an application that exercise the service as
a whole, instead of providing a server to manual test against.
merino-integration-tests-macro
This crate provides a procmacro used in merino-integration-tests. Rust
requires that procmacros be in their own crate.
Recommended Tools
- rust-analyzer - IDE-like tools for many editors. This provides easy access to type inference and documentation while editing Rust code, which can make the development process much easier.
- cargo-watch - A Cargo subcommand that re-runs a task when files change.
Very useful for things like
cargo watch -x clippyorcargo watch -x "test -- merino-adm".
Recommended Reading
These works have influenced the design of Merino.
- The Contextual Services Skeleton Actix project
- Zero to Production in Rust by Luca Palmieri
- Error Handling Isn't All About Errors, by Jane "yaahc" Lusby, from RustConf 2020.
Development Dependencies
Merino uses a Redis-based caching system, and so requires a Redis instance to connect to.
To make things simple, Redis (and any future service dependencies) can be
started with Docker Compose, using the docker-compose.yaml file in the dev/
directory. Notably, this does not run any Merino components that have source
code in this repository.
$ cd dev
$ docker-compose up
This Dockerized set up is optional. Feel free to run the dependent services by any other means as well.
Dev Helpers
The docker-compose setup also includes some services that can help during development.
- Redis Commander, http://localhost:8081 - Explore the Redis database started above.
- Statsd Logger - Receives statsd metrics emitted by Merino (and any thing else
on your system using statsd). Available through docker-compose logs. For
example with
docker-compose logs -f statsd-logger. - Kinto - Runs a local Remote Settings service that is used by "merino-adm".
- Kinto-attachments - Provides the attachment feature for the "Kinto" service.
Logging and Metrics
To get data out of Merino and into observable systems, we use metrics and logging. Each has a unique use case. Note that in general, because of the scale we work at, adding a metric or log event in production is not free, and if we are careless can end up costing quite a bit. Record what is needed, but don't go over board.
All data collection that happens in production (logging at INFO, WARN, or ERROR
levels; and metrics) should be documented in docs/data.md.
Logging
Merino uses Tracing for logging, which "is a framework for instrumenting Rust programs to collect structured, event-based diagnostic information". Below are some notes about using Tracing in Merino, but consider reading their docs for more information.
The basic way to interact with tracing is via the macros tracing::error!,
tracing::warn!, tracing::info!, tracing::debug!, and tracing::trace!.
Tracing can output logs in various formats, including a JSON format for production. In these docs we'll use a pretty, human readable format that spreads logs over multiple lines to include more information in a readable way.
Types
MozLog requires that all messages have a type value. If one is not provided,
our logging systems use "<unknown>" as a type value. All INFO, WARN, and
ERROR messages should have a type field, specified like:
#![allow(unused)] fn main() { tracing::warn!( r#type = "suggest.providers.multi.created-empty", id = %provider.id, "An empty MultiProvider was created" ); }
In general, the log message ("An empty MultiProvider was created") and the log type should both tell the reader what has happened. The difference is that the message is for humans and the type is for machines.
Type should be a dotted path to the file you're working in, with any merino-
prefix removed, ending in a code specific to the error. This does not strictly
need to follow the file system hierarchy, and stability over time is more
important than refactoring.
Levels
Tracing provides five log levels that should be familiar. This is what we mean by them in Merino:
-
ERROR- There was a problem, and the task was not completable. This usually results in a 500 being sent to the user. All error logs encountered in production are reported to Sentry and should be considered a bug. If it isn't a bug, it shouldn't be logged as an error. -
WARNING- There was a problem, but the task was able to recover. This doesn't usually affect what the user sees. Warnings are suitable for unexpected but "in-spec" issues, like a sync job not returning an empty set or using a deprecated function. These are not reported to Sentry. -
INFO- This is the default level of the production service. Use for logging that something happened that isn't a problem and we care about in production. This is the level that Merino uses for it's one-per-request logs and sync status messages. Be careful adding new per-request logs at this level, as they can be expensive. -
DEBUG- This is the default level for developers running code locally. Use this to give insight into how the system is working, but keep in mind that this will be on by default, so don't be too noisy. Generally this should summarize what's happening, but not give the small details like a log line for every iteration of a loop. Since this is off in production, there are no cost concerns. -
TRACE- This level is hidden by default in all environments, including tests. Add this for very detailed logs of what specific functions or objects are doing. To see these logs, you'll need to turn up the logging level for the area of the code you're in. See the logging settings for more details. If you add logs to figure out why something isn't working or why a test isn't passing, do so at theTRACElevel, and consider leaving them in the code for future debuggers.
Including data
If you want to log something that includes the contents of a variable, in other
libraries you might use string interpolation like
tracing::error!("could not find file: {}", file_path). This works in Tracing,
but there is a better way:
#![allow(unused)] fn main() { tracing::error!(?file_path, r#type = "file_handler.missing", "could not find file"); }
This would produce a log event like
Oct 27 15:51:35.134 ERROR merino: could not find file, file_path: "an/important/path.txt", type: "file_handler.missing"
at merino/src/file_handler.rs:65
in merino::file_handler::load
By including the file_path before the log line, it is included as structured
data. This will be machine-readable and can be used for better parsing down the
line. In general, you should prefer structured logging for including data in log
events.
Metrics
Metrics are handled by Cadence in [Statsd][] format https://www.datadoghq.com/blog/statsd/.
Unlike logging, the primary way that metrics reporting can cost a lot is in cardinality. The number of metric IDs we have and the combination of tag values that we supply. Often the number of individual events doesn't matter as much, since multiple events are aggregated together.
Testing strategies
There are four major testing strategies used in this repository: unit tests, Rust integration tests, Python contract tests, and Python load tests.
Unit Tests
Unit tests should appear close to the code they are testing, using standard Rust unit tests. This is suitable for testing complex behavior at a small scale, with fine grained control over the inputs.
#![allow(unused)] fn main() { fn add_two(n: u32) -> u32 { n + 2 } #[cfg(test)] mod tests { #[test] fn add_two_works() { assert_eq!(add_two(3), 5, "it should work"); } } }
Integration tests
Many behaviors are difficult to test as unit tests, especially details like the
URLs we expose via the web service. To test these parts of Merino, we have
merino-integration-tests, which starts a configurable instance
of Merino with mock data sources. HTTP requests can then be made to that server
in order to test its behavior.
#![allow(unused)] fn main() { #[actix_rt::test] async fn lbheartbeat_works() { merino_test( |_| (), |TestingTools { test_client, .. }| async move { let response = test_client .get("/__lbheartbeat__") .send() .await .expect("failed to execute request"); assert_eq!(response.status(), StatusCode::OK); assert_eq!(response.content_length(), Some(0)); }, ) .await } }
For more details, see the documentation of the merino-integration-tests crate.
Contract tests
The tests in the test-engineering/contract-tests directory are contract tests
that consume Merino's APIs using more opaque techniques. These tests run against
a Docker container of the service, specify settings via environment variables,
and operate on the HTTP API layer only and as such are more concerned with
external contracts and behavior. The contract tests cannot configure the server
per test.
For more details see the README.md file in the test-engineering/contract-tests
directory.
Load tests
The tests in the test-engineering/load-tests directory are load tests that
spawn multiple HTTP clients that consume Merino's API. These tests do not run on
CI. We run them manually to simulate real-world load on the Merino infrastructure.
{{#include ../../merino-admin/README.md}}
Merino Showroom
Showroom is a small JS demo to interact with Merino independent of the implementation in Firefox's UI, for testing and demonstration purposes.
To use the showroom, first start an instance of merino with
cargo run -p merino. Then, in another terminal start Showroom by running:
# From the repository root
$ cd merino-showroom
$ npm install
$ npm run dev
This will start a server on localhost:3000 that is
configured to connect to the default configuration of merino-web.
Note, Node 16 or higher is required to run Showroom.
The Release Process
This project currently follows a Continuous Delivery process, but it's gradually moving toward Continuous Deployment.
Whenever a commit is pushed to this repository's main branch, the deployment pipeline kicks in, deploying the changeset to the stage environment.
After the deployment is complete, accessing the __version__ endpoint will show the commit hash of the deployed version, which will eventually match to the one of the latest commit on the main branch (a node with an older version might still serve the request before it is shut down).
Versioning
The commit hash of the deployed code is considered its version identifier. The commit hash can be retrieved locally via git rev-parse HEAD.
Preventing deployment
Occasionally developers might want to prevent a commit from triggering the deployment pipeline. While this should be discouraged, there are some legitimate cases for doing so (e.g. docs only changes).
In order to prevent the deployment of the code from a PR when merging to main, the title of that PR must contain the [do not deploy] text. Note that, when generating the merge commit for a branch within the GitHub UI, the extened description must not be changed or care must be taken to ensure that [do not deploy] is still present.
For example:
# PR title (NOT the commit message)
doc: Add documentation for the release process [do not deploy]
While the [do not deploy] can be anywhere in the title, it is recommended to place it at its end in order to better integrate with the current PR title practices.
The deployment pipeline will analyse the message of the merge commit (which will be contain the PR title) and make a decision based on it.
Releasing to production
Developers with write access to the Merino repository can initiate a deployment to production after a Pull-Request on the Merino GitHub repository is merged to the main branch.
While any developer with write access can trigger the deployment to production, the expectation is that individual(s) who authored and merged the Pull-Request should do so, as they are the ones most familiar with their changes and who can tell, by looking at the data, if anything looks anomalous.
In general authors should feel responsible for the changes they make and shepherd throught their deployment.
Releasing to production can be done by:
- opening the CircleCI dashboard;
- looking up the pipeline named
merino <PR NUMBER>running in themain-workflow; this pipeline should either be in a running status (if the required test jobs are still running) or in the "on hold" status, with theunhold-to-deploy-to-prodbeing held; - once in the "on hold" status, with all the other jobs successfully completed, clicking on the "thumbs up" action on the
unhold-to-deploy-to-prodjob row will approve it and trigger the deployment, unblocking thedeploy-to-prodjob; - developers must monitor the Merino Application & Infrastructure dashboard for any anomaly, for example significant changes in HTTP response codes, increase in latency, cpu/memory usage (most things under the infrastructure heading).
What to do if production is broken?
Don't panic and follow the instructions below:
- depending on the severity of the problem, decide if this warrants kicking off an incident;
- if the root cause of the problem can be identified in a relatively small time, create a PR for the fix.
- verify the fix locally;
- verify the fix on
stage, after it is reviewed by a Merino developer and merged; - deploy it to production.
OR
- if the root cause of the problem is harder to track down, revert the last commit and then deploy the revert commit to production.
Choosing a logging library for Merino
- Status: accepted
- Date: 2021-05-11
Tracking issue: mozilla-services/merino#15
Context and Problem Statement
Merino needs a system to produce logging. Rust has several options to do this, with no clear winner. What library should Merino use?
The log Crate
There is a de facto standard logging library for Rust,
log. It is an important part of the decision,
but it is not a solution to the problem: it is a logging facade that provides
a way for libraries to produce their own logs, but does not provide any logging
capabilities itself. Without a logger crate to use it with, the logs compile
away to nothing.
Decision Drivers
- Sentry integration should be available
- MozLog format should be supported
- There should be both human and machine friendly logging output options.
- Library compatibility
Considered Options
- Something from the
logecosystem
Decision Outcome
Option 2 - Tracing. Although Slog has more momentum at this time, Tracing sets us up for a better set of tools long term.
Pros and Cons of the Options
Option 1 - Slog
slogis an ecosystem of reusable components for structured, extensible, composable and contextual logging for Rust.
Slog's first release was 0.1.0 in June of 2016, and it's 1.0 release was in September of 2016.
To use it, developers create logger objects that provide methods to produce log lines and create sub-loggers. These loggers must be passed to lower level code explicitly to be used.
Slog is compatible with the de facto log crate. Log lines emitted using that
system (such as by libraries) can be routed to a logger object, with no loss of
detail. Few libraries use slog directly, and none of the libraries that are
currently used in Merino do at all. Since libraries aren't using slog, it will
be harder to make them participate in the logging hierarchy.
Structured logging is supported. Logs can carry associated data, which can aid in the machine readability of logs.
The tree of loggers is built explicitly through the loggers objects, and subloggers must be aware of superloggers, since the only way to get a sublogger is to call a method on a logger. This separates the logging structure from the call stack, but makes it awkward to recover that information should it be helpful. This means that logging generally has to be passed as arguments to many functions, making the tree of loggers less flexible.
The Sentry library for Rust has support for slog. There is a a MozLog crate for slog that Mozilla wrote.
- Good, because structured logging helps provide more useful logs.
- Good, because it has Sentry integration.
- Good, because it already has MozLog integration.
- Bad, because it has little library support.
- Bad, because explicitly building the logging tree is rigid.
Option 2 - Tracing
tracingis a framework for instrumenting Rust programs to collect structured, event-based diagnostic information.
Tracing's first release was 0.0.0 in November of 2017. It has not had a 1.0 release. It's latest release is 0.1.26, published April 2021.
To use it, developers set up a global or scope-based subscriber of logs, which
collects spans and events that are generated in the code. Spans can be
entered and exited. During the time between these, all spans and events are
associated with the entered span as their parent. This association happens
explicitly, and can cross call boundaries. However, spans can be entered and
exited in more fine grained ways if needed.
Tracing is compatible with the de facto log crate. Log lines emitted using
that system are seen as events in Tracing, with no loss of detail.
Structured logging is supported. Both spans and events can carry associated data. This data can be accessed hierarchically, building up a context of execution.
The tree of spans is built by entering spans. Loggers do not have to be aware of their parents, their logs are placed in the context of whatever set of spans has been entered at that moment. because [ one like we did with slog.
Tracing is developed as a part of the Tokio ecosystem, the same that our web
framework (Actix), http client (Reqwest), and async runtime (Tokio) are
developed under. It has some library support. Additionally, since the tree of
spans is built more implicitly, libraries that use the log facade can
participate in our structured logging.
- Good, because structured logging helps provide more useful logs.
- Good, because it has good integration into the libraries we use.
- Good, because implicitly building the logging hierarchy and context is flexible.
- Bad, because it lacks Sentry support.
- Bad, because it lacks MozLog support.
Option 3 - Something in the log ecosystem
This option was not considered deeply because log does not support structured
logging. Not being able to attach concrete data to logs makes much of the
logging tasks much harder.
- Bad, because it lacks structured logging.
/*!
Choosing a logging library for Merino
- Status: accepted
- Date: 2021-07-28
Tracking issue: N/A
Context and Problem Statement
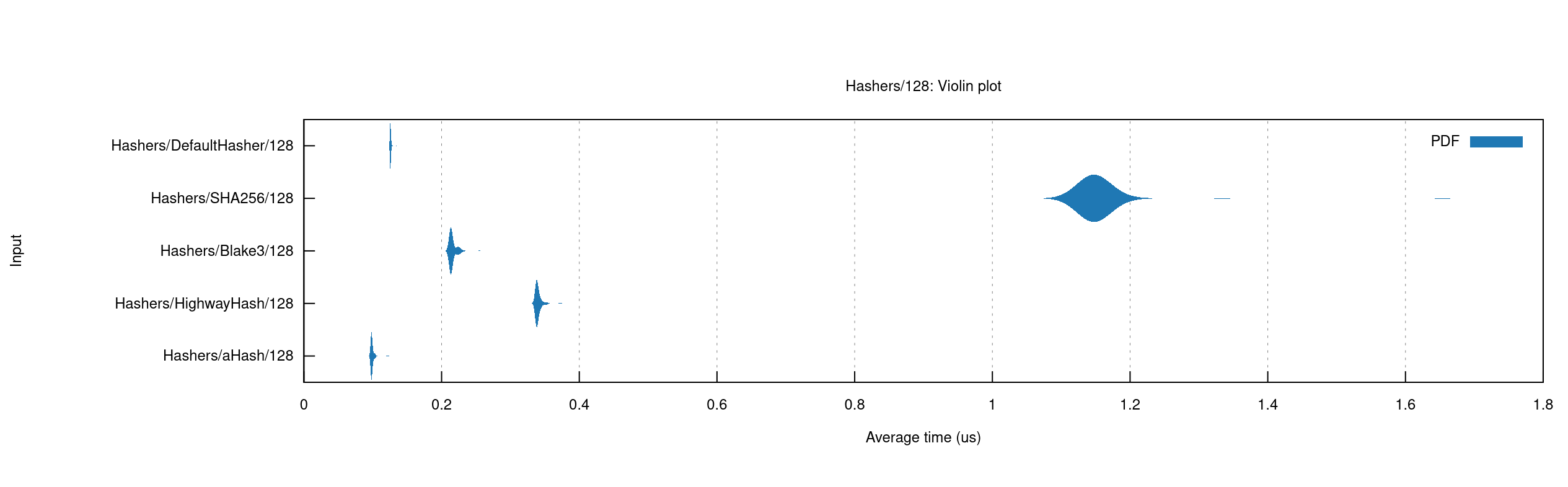
Merino needs a way to generate cache keys for items it will store in the cache. A natural way to do this is by hashing the input, and using the result of the hash for the cache key. There are many hash keys available. Which one should Merino use?
Decision Drivers
- For Merino's common workloads, generating a hash should be low latency.
- The items that Merino hashes are relatively small, a few dozen bytes plus the user's query.
- Hashes should be stable across time (on multiple version of Merino) and space (on multiple instances of the same version of Merino).
- HashDoS protection is not a concern.
Considered Options
- SipHash
- aHash
- rustc-hash (aka FxHasher)
- HighwayHash
- sha256 or similar
- Blake3
Decision Outcome
Chosen option: option 6, Blake3, because it is network-safe, and very fast.
Pros and Cons of the Options
Option 1 - SipHash
SipHash is a non-cryptographic hash algorithm used by default for Rust's hashing needs, such as HashMaps. It is designed primarily to be resistent against "HashDoS" attacks, in which an attacker can force hash collisions in a system and overwhelm data structures like hashmaps and caches. It is faster than most cryptographic hashes, such as sha256, but is generally slower than other hashes considered.
In Rust's standard library, the standard way to use SipHash is with
std::collections::hash_map::DefaultHasher, which is not guaranteed to produce
stable output over time. Specifically, DefaultHasher may change to hashing
algorithm besides SipHash in the future.
- Good, because it is widely tested by Rust
- Good, because it is already available in the standard library
- Bad, because it spends resources on hashdos protection, which we don't need
- Bad, because Rust's
DefaultHashis the normal way to use it, andDefaultHashmay change in the future.
Option 2 - aHash
AHash is designed with the explicit purpose of being the fastest HashDOS resistant hash available in Rust. It is also designed specifically to be used for in-memory hashmaps, and is not guaranteed to be stable over time or space.
This would be a viable candidate for any case where Merino uses in-memory hashmaps that need high performance, but is not suitable for network hashing, such as for Redis keys.
- Good, because it is very fast
- Bad, because it is not network-safe
Option 3 - rustc-hash aka FxHash
https://crates.io/crates/rustc-hash
This is the hashing algorithm used internally by the Rust compiler, and is used in some places in Firefox. It is also not designed to be network safe, though it may be by accident. It is comparable in speed to aHash, depending on the input. It is not resistant against HashDoS attacks, since it is not a keyed hashing algorithm.
Notably, the aHash hash comparison suite claims that it is easy to accidentally produce self-DoS conditions with this hashing algorithm, if the hash inputs are not well chosen.
- Good, because it is used in rustc and Firefox
- Good, because it is relatively fast
- Bad, because it is not intended to be network safe
- Bad, because of claims about extreme weakness against DoS, including self-DoS
Option 4 - HighwayHash
HighwayHash is an algorithm developed by Google designed to be network safe, strong against DoS attacks, and SIMD-optimized. It is recommended by the aHash README as a better choice in "network use or in applications which persist hashed values".
Notably, HighwayHash is relatively slow for small hash inputs, but relatively fast for larger ones (though still not as fast as most non-network-safe algorithms). Merino's hash inputs are near the boundary where it starts to be faster than it's competition.
There is a predecessor to HighwayHash, FarmHash (and CityHash before it), that are faster for smaller inputs. However, the libraries for these aren't maintained anymore.
- Good, because it is relatively fast
- Good, because it is designed to be network-safe
- Good, because it is a "frozen" by Google, and won't change in the future
- Good, because it is actively maintained.
- Bad, because it's relatively slow for smaller keys.
Option 5 - sha256 or similar
The SHA family of hashes are network and DoS safe. However, due to being cryptographic hash functions are notably slower than non-cryptographic hashes. For purposes where speed is not an issue, they are exceptionally safe and well tested algorithms that should be considered.
- Good, because it is very safe
- Good, because it is very widely used and studied
- Bad, because it is slow
- Bad, because we pay for unneeded features
Option 6 - Blake3
Blake3 is a cryptographic hash function designed to be highly parallizable and extremely fast. Being a cryptographic hash, it is network-safe, and Hash-DoS resistant. It is however much faster than most cryptographic algorithms, competing with the other fast algorithms considered here. It is a relatively new hash, first published in January of 2020.
- Good, because it is ver safe
- Good, because it very fast
- Good, because it can be parallizable for large payloads
- Bad, because it is relatively young
Other resources
- The Rust Performance Book :: Hashing
- aHash's hash comparison suite
- SipHash
- aHash
- rustc-hash (aka FxHasher)
- HighwayHash
Benchmarking results for hashing 128 byte values
*/