tldr; Cliquet est un toolkit Python pour construire des APIs, qui implémente les bonnes pratiques en terme de mise en production et de protocole HTTP.
Les origines
L'objectif pour le premier trimestre 2015 était de construire un service de stockage et de synchronisation de listes de lecture.
Au démarrage du projet, nous avons tenté de rassembler toutes les bonnes pratiques et recommandations, venant de différentes équipes et surtout des derniers projets déployés.
De même, nous voulions tirer parti du protocole de Firefox Sync, robuste et éprouvé, pour la synchronisation des données «offline».
Plutôt qu'écrire un énième article de blog, nous avons préféré les rassembler dans ce qu'on a appellé «un protocole».
Comme pour l'architecture envisagée nous avions deux projets à construire, qui devaient obéir globalement à ces mêmes règles, nous avons décidé de mettre en commun l'implémentation de ce protocole et de ces bonnes pratiques dans un «toolkit».
Cliquet est né.
Les intentions
Quelle structure JSON pour mon API ? Quelle syntaxe pour filtrer la liste via la querystring ? Comment gérer les écritures concurrentes ? Et synchroniser les données dans mon application cliente ?
Désormais, quand un projet souhaite bénéficier d'une API REST pour stocker et consommer des données, il est possible d'utiliser le protocole HTTP proposé et de se concentrer sur l'essentiel. Cela vaut aussi pour les clients, où la majorité du code d'interaction avec le serveur est réutilisable.
Comment pouvons-nous vérifier que le service est opérationnel ? Quels indicateurs StatsD ? Est-ce que Sentry est bien configuré ? Comment déployer une nouvelle version sans casser les applications clientes ?
Comme Cliquet fournit tout ce qui est nécessaire pour être conforme avec les exigences de la mise en production, le passage du prototype au service opérationnel est très rapide ! De base le service répondra aux attentes en terme supervision, configuration, déploiement et dépréciation de version. Et si celles-ci évoluent, il suffira de faire évoluer le toolkit.
Quel backend de stockage pour des documents JSON ? Comment faire si l'équipe de production impose PostgreSQL ? Et si on voulait passer à Redis ou en mémoire pour lancer les tests ?
En terme d'implémentation, nous avons choisi de fournir des abstractions. En effet, nous avions deux services dont le coeur consistait à exposer un CRUD en REST, persistant des données JSON dans un backend. Comme Pyramid et Cornice ne fournissent rien de tout prêt pour ça, nous avons voulu introduire des classes de bases pour abstraire les notions de resource REST et de backend de stockage.
Dans le but de tout rendre optionnel et «pluggable», tout est configurable depuis le fichier .ini de l'application. Ainsi tous les projets qui utilisent le toolkit se déploieront de la même manière : seuls quelques éléments de configuration les distingueront.

Le protocole
Est-ce suffisant de parler d'«API REST» ? Est-ce bien nécessaire de relire la spec HTTP à chaque fois ? Pourquoi réinventer un protocole complet à chaque fois ?
Quand nous développons un (micro)service Web, nous dépensons généralement beaucoup trop d'énergie à (re)faire des choix (arbitraires).
Nul besoin de lister ici tout ce qui concerne la dimension de la spécification HTTP pure, qui nous impose le format des headers, le support de CORS, la négocation de contenus (types mime), la différence entre authentification et autorisation, la cohérence des code status...
Les choix principaux du protocole concernent surtout :
- Les resources REST : Les deux URLs d'une resource (pour la collection et les enregistrements) acceptent des verbes et des headers précis.
- Les formats : le format et la structure JSON des réponses est imposé, ainsi que la pagination des listes ou la syntaxe pour filtrer/trier les resources via la querystring.
- Les timestamps : un numéro de révision qui s'incrémente à chaque opération d'écriture sur une collection d'enregistrements.
- La synchronisation : une série de leviers pour récupérer et renvoyer des changements sur les données, sans perte ni collision, en utilisant les timestamps.
- Les permissions : les droits d'un utilisateur sur une collection ou un enregistrement (encore frais et sur le point d'être documenté) [1].
- Opérations par lot: une URL qui permet d'envoyer une série de requêtes décrites en JSON et d'obtenir les réponses respectives.
Dans la dimension opérationnelle du protocole, on trouve :
- La gestion de version : cohabitation de plusieurs versions en production, avec alertes dans les entêtes pour la fin de vie des anciennes versions.
- Le report des requêtes : entêtes interprétées par les clients, activées en cas de maintenance ou de surchage, pour ménager le serveur.
- Le canal d'erreurs : toutes les erreurs renvoyées par le serveur ont le même format JSON et ont un numéro précis.
- Les utilitaires : URLs diverses pour répondre aux besoins exprimés par l'équipe d'administrateurs (monitoring, metadonnées, paramètres publiques).
Ce protocole est une compilation des bonnes pratiques pour les APIs HTTP (c'est notre métier !), des conseils des administrateurs système dont c'est le métier de mettre à disposition des services pour des millions d'utilisateurs et des retours d'expérience de l'équipe de Firefox Sync pour la gestion de la concurrence et de l'«offline-first».
Il est documenté en détail.
Dans un monde idéal, ce protocole serait versionné, et formalisé dans une RFC. En rêve, il existerait même plusieurs implémentations avec des technologies différentes (Python, Go, Node, etc.). [2]
| [1] | Voir notre article dédié sur les permissions |
| [2] | Rappel: nous sommes une toute petite équipe ! |
Le toolkit
Choix techniques
Cliquet implémente le protocole en Python (2.7, 3.4+, pypy), avec Pyramid [3].
Pyramid est un framework Web qui va prendre en charge tout la partie HTTP, et qui s'avère pertinent aussi bien pour des petits projets que des plus ambitieux.
Cornice est une extension de Pyramid, écrite en partie par Alexis et Tarek, qui permet d'éviter d'écrire tout le code boilerplate quand on construit une API REST avec Pyramid.
Avec Cornice, on évite de réécrire à chaque fois le code qui va cabler les verbes HTTP aux méthodes, valider les entêtes, choisir le sérialiseur en fonction des entêtes de négociation de contenus, renvoyer les codes HTTP rigoureux, gérer les entêtes CORS, fournir la validation JSON à partir de schémas...
Cliquet utilise les deux précédents pour implémenter le protocole et fournir des abstractions, mais on a toujours Pyramid et Cornice sous la main pour aller au delà de ce qui est proposé !
| [3] | Au tout début nous avons commencé une implémentation avec Python-Eve (Flask), mais n'étions pas satisfaits de l'approche pour la configuration de l'API. En particulier du côté magique. |
Concepts
Bien évidemment, les concepts du toolkit reflètent ceux du protocole mais il y a des éléments supplémentaires:
- Les backends : abstractions pour le stockage, le cache et les permissions (ex. PostgreSQL, Redis, en-mémoire, ...)
- La supervision : logging JSON et indicateurs temps-réel (StatsD) pour suivre les performances et la santé du service.
- La configuration : chargement de la configuration depuis les variables d'environnement et le fichier .ini
- La flexibilité : dés/activation ou substitution de la majorité des composants depuis la configuration.
- Le profiling : utilitaires de développement pour trouver les goulets d'étranglement.
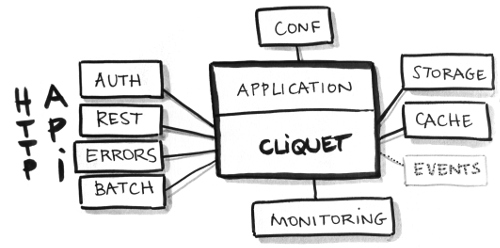
Proportionnellement, l'implémentation du protocole pour les resources REST est la plus volumineuse dans le code source de Cliquet. Cependant, comme nous l'avons décrit plus haut, Cliquet fournit tout un ensemble d'outillage et de bonnes pratiques, et reste donc tout à fait pertinent pour n'importe quel type d'API, même sans manipulation de données !
L'objectif de la boîte à outils est de faire en sorte qu'un développeur puisse constuire une application simplement, en étant sûr qu'elle réponde aux exigeances de la mise en production, tout en ayant la possibilité de remplacer certaines parties au fur et à mesure que ses besoins se précisent.
Par exemple, la persistence fournie par défault est schemaless (e.g JSONB), mais rien n'empêcherait d'implémenter le stockage dans un modèle relationnel.
Comme les composants peuvent être remplacés depuis la configuration, il est tout à fait possible d'étendre Cliquet avec des notions métiers ou des technologies exotiques ! Nous avons posé quelques idées dans la documentation de l'éco-système.
Dans les prochaines semaines, nous allons introduire la notion d'«évènements» (ou signaux), qui permettraient aux extensions de s'interfacer beaucoup plus proprement.
Nous attachons beaucoup d'importance à la clareté du code, la pertinence des patterns, des tests et de la documentation. Si vous avez des commentaires, des critiques ou des interrogations, n'hésitez pas à nous en faire part !
Cliquet, à l'action.
Nous avons écrit un guide de démarrage, qui n'exige pas de connaître Pyramid.
Pour illustrer la simplicité et les concepts, voici quelques extraits !
Étape 1
Activer Cliquet:
import cliquet
from pyramid.config import Configurator
def main(global_config, **settings):
config = Configurator(settings=settings)
cliquet.initialize(config, '1.0')
return config.make_wsgi_app()
À partir de là, la plupart des outils de Cliquet sont activés et accessibles.
Par exemple, les URLs hello (/v1/) ou supervision (/v1/__heartbeat__). Mais aussi les backends de stockage, de cache, etc. qu'il est possible d'utiliser dans des vues classiques Pyramid ou Cornice.
Étape 2
Ajouter des vues:
def main(global_config, **settings):
config = Configurator(settings=settings)
cliquet.initialize(config, '1.0')
config.scan("myproject.views")
return config.make_wsgi_app()
Pour définir des resources CRUD, il faut commencer par définir un schéma, avec Colander, et ensuite déclarer une resource:
from cliquet import resource, schema
class BookmarkSchema(schema.ResourceSchema):
url = schema.URL()
@resource.register()
class Bookmark(resource.BaseResource):
mapping = BookmarkSchema()
Désormais, la resource CRUD est disponible sur /v1/bookmarks, avec toutes les fonctionnalités de synchronisation, filtrage, tri, pagination, timestamp, etc. De base les enregistrements sont privés, par utilisateur.
$ http GET "http://localhost:8000/v1/bookmarks"
HTTP/1.1 200 OK
...
{
"data": [
{
"url": "http://cliquet.readthedocs.io",
"id": "cc103eb5-0c80-40ec-b6f5-dad12e7d975e",
"last_modified": 1437034418940,
}
]
}
Étape 3
Évidemment, il est possible choisir les URLS, les verbes HTTP supportés, de modifier des champs avant l'enregistrement, etc.
@resource.register(collection_path='/user/bookmarks',
record_path='/user/bookmarks/{{id}}',
collection_methods=('GET',))
class Bookmark(resource.BaseResource):
mapping = BookmarkSchema()
def process_record(self, new, old=None):
if old is not None and new['device'] != old['device']:
device = self.request.headers.get('User-Agent')
new['device'] = device
return new
Plus d'infos dans la documentation dédiée !
Note
Il est possible de définir des resources sans validation de schema. Voir le code source de Kinto.
Étape 4 (optionelle)
Utiliser les abstractions de Cliquet dans une vue Cornice.
Par exemple, une vue qui utilise le backend de stockage:
from cliquet import Service
score = Service(name="score",
path='/score/{game}',
description="Store game score")
@score.post(schema=ScoreSchema)
def post_score(request):
collection_id = 'scores-' + request.match_dict['game']
user_id = request.authenticated_userid
value = request.validated # c.f. Cornice.
storage = request.registry.storage
record = storage.create(collection_id, user_id, value)
return record
Vos retours
N'hésitez pas à nous faire part de vos retours ! Cela vous a donné envie d'essayer ? Vous connaissez un outil similaire ? Y-a-t-il des points qui ne sont pas clairs ? Manque de cas d'utilisation concrets ? Certains aspects mal pensés ? Trop contraignants ? Trop de magie ? Overkill ?
Nous prenons tout.
Points faibles
Nous sommes très fiers de ce que nous avons construit, en relativement peu de temps. Et comme nous l'exposions dans l'article précédent, il y a du potentiel !
Cependant, nous sommes conscients d'un certain nombre de points qui peuvent être vus comme des faiblesses.
- La documentation d'API : actuellement, nous n'avons pas de solution pour qu'un projet qui utilise Cliquet puisse intégrer facilement toute la documentation de l'API obtenue.
- La documentation : il est très difficile d'organiser la documentation, surtout quand le public visé est aussi bien débutant qu'expérimenté. Nous sommes probablement victimes du «curse of knowledge».
- Le protocole : on sent bien qu'on va devoir versionner le protocole. Au moins pour le désolidariser des versions de Cliquet, si on veut aller au bout de la philosophie et de l'éco-système.
- Le conservatisme : Nous aimons la stabilité et la robustesse. Mais surtout nous ne sommes pas tout seuls et devons nous plier aux contraintes de la mise en production ! Cependant, nous avons très envie de faire de l'async avec Python 3 !
- Publication de versions : le revers de la médaille de la factorisation. Il arrive qu'on préfère faire évoluer le toolkit (e.g. ajouter une option) pour un point précis d'un projet. En conséquence, on doit souvent releaser les projets en cascade.
Quelques questions courantes
Pourquoi Python ?
On prend beaucoup de plaisir à écrire du Python, et le calendrier annoncé initialement était très serré: pas question de tituber avec une technologie mal maitrisée !
Et puis, après avoir passé près d'un an sur un projet Node.js, l'équipe avait bien envie de refaire du Python.
Pourquoi pas Django ?
On y a pensé, surtout parce qu'il y a plusieurs fans de Django REST Framework dans l'équipe.
On l'a écarté principalement au profit de la légèreté et la modularité de Pyramid.
Pourquoi pas avec un framework asynchrone en Python 3+ ?
Pour l'instant nos administrateurs système nous imposent des déploiements en Python 2.7, à notre grand désarroi /o\
Pour Reading List, nous avions activé gevent.
Puisque l'approche consiste à implémenter un protocole bien déterminé, nous n'excluons pas un jour d'écrire un Cliquet en aiohttp ou Go si cela s'avèrerait pertinent.
Pourquoi pas JSON-API ?
Comme nous l'expliquions au retour des APIdays, JSON-API est une spécification qui rejoint plusieurs de nos intentions.
Quand nous avons commencé le protocole, nous ne connaissions pas JSON-API. Pour l'instant, comme notre proposition est beaucoup plus minimaliste, le rapprochement n'a pas dépassé le stade de la discussion.
Est-ce que Cliquet est un framework REST pour Pyramid ?
Non.
Au delà des classes de resources CRUD de Cliquet, qui implémentent un protocole bien précis, il faut utiliser Cornice ou Pyramid directement.
Est-ce que Cliquet est suffisamment générique pour des projets hors Mozilla ?
Premièrement, nous faisons en sorte que tout soit contrôlable depuis la configuration .ini pour permettre la dés/activation ou substitution des composants.
Si le protocole HTTP/JSON des resources CRUD vous satisfait, alors Cliquet est probablement le plus court chemin pour construire une application qui tient la route.
Mais l'utilisation des resources CRUD est facultative, donc Cliquet reste pertinent si les bonnes pratiques en terme de mise en production ou les abstractions fournies vous paraissent valables !
Cliquet reste un moyen simple d'aller très vite pour mettre sur pied une application Pyramid/Cornice.
Est-ce que les resources JSON supporte les modèles relationnels complexes ?
La couche de persistence fournie est très simple, et devrait répondre à la majorité des cas d'utilisation où les données n'ont pas de relations.
En revanche, il est tout à fait possible de bénéficier de tous les aspects du protocole en utilisant une classe Collection maison, qui se chargerait elle de manipuler les relations.
Le besoin de relations pourrait être un bon prétexte pour implémenter le protocole avec Django REST Framework :)
Est-il possible de faire ci ou ça avec Cliquet ?
Nous aimerions collecter des besoins pour écrire un ensemble de «recettes/tutoriels». Mais pour ne pas travailler dans le vide, nous aimerions connaitre vos idées ! (ex. brancher l'authentification Github, changer le format du logging JSON, stocker des données cartographiques, ...)
Est-ce que Cliquet peut manipuler des fichiers ?
Nous l'envisageons, mais pour l'instant nous attendons que le besoin survienne en interne pour se lancer.
Si c'est le cas, le protocole utilisé sera Remote Storage, afin notamment de s'intégrer dans l'éco-système grandissant.
Est-ce que la fonctionnalité X va être implémentée ?
Cliquet est déjà bien garni. Plutôt qu'implémenter la fonctionnalité X, il y a de grandes chances que nous agissions pour s'assurer que les abstractions et les mécanismes d'extension fournis permettent de l'implémenter sous forme d'extension.