Note
Translated from the French by Dan Phrawzty.
tl;dr Cliquet is a Python toolkit for building APIs that implements best practices in terms of production use and the HTTP protocol.
The Origins
The objective for the first trimester of 2015 was to build a service for storage and the synchronisation of a reading list. At the outset of the project we tried assembling all of the best practices and recommendations from different teams and currently deployed projects. Also, we wanted to take advantage of the Firefox Sync protocol for offline sync since it's robust and proven.
Rather than write yet another article we decided to assemble what was already out there into a more formalised protocol.
At the time we had two projects in the pipeline that obeyed more or less the same rules, so we decided go with a common implementation of these best practices (and resulting protocol) in the form of a re-usable toolkit.
Cliquet was born.
The Intentions
What JSON structure should I use for my API? Which syntax for filtering the querystring? How do I deal with concurrent writes? And what about synchronising data on the client-side?
Today, when a new project wants to take advantage of a REST API for storing and consuming data, it is entirely reasonable to use the stock HTTP protocol and to concentrate only on the bare essentials. This goes for the clients as well, since the majority of code that handles interaction with the server is reusable.
How can I verify if the service is operational? How about StatsD? Is Sentry configured properly? How can I deploy a new version without breaking client apps?
Cliquet provides everything you need to get you started in production - by design, the transition from prototype to operational service is smooth and rapid. Out of the box, the service will have facilities for monitoring and configuration, as well as aides for deployment and version deprecation. As these realities evolve in the real world, so does the toolkit.
Which storage backend should I use for the JSON documents? What happens if the Ops team mandates that we use PostgreSQL? And what if we want to switch to a Redis, or even memory-based backend, for local testing and development?
One word: abstraction. This concept lies at the heart of our our entire implementation. Those two projects mentioned previously were, at their most simple, HTTP services that exposed a CRUD REST API backed by persistent JSON data stores. Since neither Pyramid nor Cornice (which we'll touch on later) were quite ready to handle this situation, we decided to introduce some classes to abstract the rudiments of both the REST model and of storage backends in general.
An important tenet in all of our projects is that of flexibility. This means that we try to make things optional where we can (and malleable where we can't) - Cliquet is no different. Everything is configurable right from the .ini file! What's more, all of the projects that use the toolkit are deployed in exactly the same way - only the configuration is different.

The Protocol
Is a REST API sufficient? Is it really necessary to re-read the HTTP spec every time? Why are we reinventing the same protocol over and over?
As a group, web developers tend to spend way too much energy on reinventing the wheel with every project, which is especially heinous since many of the decisions are arbitrary at best. This behaviour can at least partially explained by the sheer immensity of the HTTP specification, and all which it contains, including header formats, CORS support, content negotiation and mime types - not to mention trickier topics like the difference between authentication and authorisation, and how to interpret HTTP status codes...
In Cliquet, these are the principal questions we sought to answer definitively:
- REST resources: The two URLs of a resource (one each for collections and records) accept verbs and precise headers.
- Formats: The structure of the JSON responses, as well as the pagination of lists, or the syntax for filtering and sorting of resources via the querystring.
- Timestamps: A revision counter that is auto-incremented with every write operation in a collection.
- Synchronisation: Levers to retrieve and send changes to the data (without loss or collision) using timestamps.
- Permissions: Specifically, user-level permissions on a collection or a record. (This is a work in progress) [1].
- Batch operations: A URL that accepts a series of JSON-formatted requests and provides the response(s).
From an operational perspective we looked at the following:
- Version control: The cohabitation of multiple versions in production along with alerts in the headers for versions which are end-of-life.
- Deferred requests: Client headers that can be activated during periods of maintenance or heavy usage - the idea being to help save the server from extraneous load.
- Error channel: All errors returned by the server have the same JSON format and a specific identifier.
- Utilities: Various URLs that expose select metadata, public settings, and other highly monitorable information (to keep your local sysadmin happy).
The Cliquet protocol is thus a compilation of:
- Best practices for HTTP APIs (it's what we do for a living, after all);
- Advice from senior system administrators whose jobs it is to maintain services for the many millions of Firefox users;
- Feedback from the Firefox Sync team regarding concurrency management and "offline-first" design.
Want to know more? No problem since it's documented in great detail.
In an ideal world this protocol would be versioned and formalised in an RFC. Perhaps there would even be several implementations in different languages. [2]
| [1] | See our dedicated article on permissions in Cliquet. |
| [2] | Bear in mind that we're a very small team! |
The Toolkit
Technical Choices
Cliquet, the protocol, is currently implemented in Python (2.7, 3.4+, pypy) with Pyramid [3].
Pyramid is a web framework that is responsible for all things HTTP; it is usable by projects of all sizes, great and small.
Cornice is an extension for Pyramid written by Alexis and Tarek that consists of reusable boilerplate code. The goal here is to avoid reinventing the wheel each time when building a REST API with Pyramid. Cornice handles the plumbing for things like HTTP verbs and methods, header validation, content negotiation, HTTP return codes, CORS headers, JSON schema validation, and so forth.
Cliquet, in turn, uses both Pyramid and Cornice to implement the protocol and provide the necessary abstractions; both remain available for expanding and extending from what comes in the box.
| [3] | We started with an implementation using Python-Eve (Flask) but we weren't satisified with the API configuration process - too much hand-waving and black magic for our taste. |
Concepts
Conceptually the toolkit reflects the protocol - there are some interesting additional elements, however:
- Backends: Abstractions for storage, caching, and permissions (ex. PostgreSQL, Redis, in-memory, etc.)
- Monitoring: JSON-formatted logs and real-time instrumentation (StatsD) to keep tabs on performance and health.
- Configuration: The configuration itself can be loaded from environment variables or the .ini file - or a combination of both.
- Flexibility: Most of the components can be turned on or off (or substituted completely) via the configuration alone.
- Profiling: Built-in development utilities to help find bottlenecks.
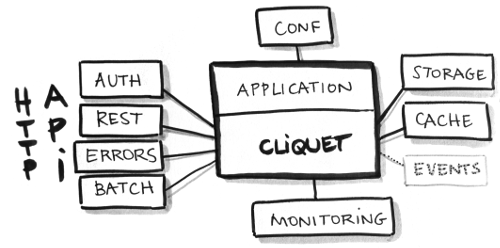
By proportion, the number of lines of code that are necessary to support REST outweighs that of any other component in Cliquet. This is a feature; Cliquet provides a wide range of functionality and can therefore be used in any number of contexts (even without manipulating data).
The primary objective of the toolkit is aid the developer in building their application with a minimum of fuss. You mix and match only what you need, and every component is guaranteed to be production-ready.
For example, the persistence furnished by default is schemaless (e.g. JSONB) but there's no reason a relational storage model couldn't be implemented. Since all of the moving parts can be replaced directly via the configuration, it's entirely feasible to extend Cliquet with business logic or other exotic elements. We've got even more ideas in the "ecosystem" portion of our documentation.
In a few weeks well be introducing the idea of "events" (or "signals") which will allow plugins to interface in a much cleaner way.
We put a high value on code readability, as well as the importance of patterns, tests, and documentation. If you have any feedback, suggestions, accolades, or criticisms, don't hesitate to let us know!
Cliquet in Action!
We wrote a quickstart guide that requires no knowledge of Pyramid.
Here are some examples to illustrate how straightforward Cliquet can be!
Step 1
Activate Cliquet:
import cliquet
from pyramid.config import Configurator
def main(global_config, **settings):
config = Configurator(settings=settings)
cliquet.initialize(config, '1.0')
return config.make_wsgi_app()
From here, most of the features of Cliquet are active and ready to be used.
For example, the hello (/v1/) or monitoring (/v1/__heartbeat__) URLs, but also the storage and cache backends that are available in the classic views in either Pyramid or Cornice.
Step 2
Add some views:
def main(global_config, **settings):
config = Configurator(settings=settings)
cliquet.initialize(config, '1.0')
config.scan("myproject.views")
return config.make_wsgi_app()
The first step in defining a CRUD resource is to define the schema with Colander:
from cliquet import resource, schema
class BookmarkSchema(schema.ResourceSchema):
url = schema.URL()
@resource.register()
class Bookmark(resource.BaseResource):
mapping = BookmarkSchema()
From here, the CRUD resource is available at /v1/bookmarks with all the synchronisation, filtering, sorting, paging, and timestamp features ready to go. By default the records are private (per user).
$ http GET "http://localhost:8000/v1/bookmarks"
HTTP/1.1 200 OK
...
{
"data": [
{
"url": "http://cliquet.readthedocs.io",
"id": "cc103eb5-0c80-40ec-b6f5-dad12e7d975e",
"last_modified": 1437034418940,
}
]
}
Step 3
There's lots of room to change things up, such as the URLs and HTTP verbs, or even modifying the fields before they're saved.
@resource.register(collection_path='/user/bookmarks',
record_path='/user/bookmarks/{{id}}',
collection_methods=('GET',))
class Bookmark(resource.BaseResource):
mapping = BookmarkSchema()
def process_record(self, new, old=None):
if old is not None and new['device'] != old['device']:
device = self.request.headers.get('User-Agent')
new['device'] = device
return new
For more information, see the resource documentation .
Step 4 (optional)
Let's try using Cliquet abstractions in a Cornice view:
from cliquet import Service
score = Service(name="score",
path='/score/{game}',
description="Store game score")
@score.post(schema=ScoreSchema)
def post_score(request):
collection_id = 'scores-' + request.match_dict['game']
user_id = request.authenticated_userid
value = request.validated # c.f. Cornice.
storage = request.registry.storage
record = storage.create(collection_id, user_id, value)
return record
Feedback
Have something you'd like to say? Want to get involved? Great! We love community contributions and would be glad to help you get started.
Areas for improvement
We're quite proud of what we've built in a relatively short time frame, and as we noted in a previous article, there's a lot of potential just waiting to be tapped. Nonetheless, we are aware of a few areas where we could improve things - maybe you'd like to help?
- API Documenatation: Right now we don't have a good solution for a project based on Cliquet to easily integrate all of the API documentation.
- Documentation in general: It's difficult to write, organise, and maintain documentation, especially when it's aimed at a general public that runs the gamut from absolute beginner to expert. We are victims of the "curse of knowledge".
- Protocol: At some point we're going to have to properly version the protocol, which means making a division within versions of Cliquet itself; this will be necessary if we want to move the ecosystem forward.
- Conservatism: We're fans of stability and robustness, but we don't live in a vacuum and must therefore sometimes bend to the realities of the real world. Moving forward with Python 3 is a part of this (async is a good target).
- Releases: The flip side of factoring. Occasionally we add features or otherwise evolve the toolkit as a response to the requirements of a specific project. As a result, we end up having to do waterfall-style project releases.
Common Questions
Why Python?
The simple answer is that we like Python! Seriously though, the fact of the matter was that our timetable was pretty tight - we didn't have time to learn a new language.
That and the fact the whole time had just spent on a year on a Node.js project from which we needed to recover.
Why not Django?
We definitely considered it, especially given the number of fans of the Django REST Framework in the team. Ultimately we decided that the flexibility of Pyramid's lightweight framework was a better fit.
Why not an async framework in Python 3?
At the time, the Mozilla Operations team supported only Python 2.7 in production (much to our chagrin).
For Reading List we activated gevent.
That said, since our only goal is to implement a well-defined protocol, we may some day write Cliquet in aiohttp or Go if the opportunity presents itself.
Why not JSON-API?
Like we mentioned in a previous post (fr), JSON-API is a specification that touches on a lot of what we wanted - we didn't know about it when we started with our own protocol. Since our proposition is pretty minimalist in comparison, the idea of integrating JSON-API hasn't progressed beyond the discussion phase yet.
Is Cliquet a REST framework for Pyramid?
No.
Beyond the CRUD resources classes in Cliquet (which implement a highly specific protocol), you must use Cornice or Pyramid directly.
Is Cliquet sufficiently generic for non-Mozilla projects?
Yes!
It's designed from the ground up such that every component can be turned on or off, or substituted entirely, right from the configuration file (or from the environment).
If the combination of HTTP, JSON, and CRUD resources satisfies your use case, then Cliquet is a pretty safe bet for you new application. Combined with a design based on production best practices and handy abstractions, Cliquet offers a straightforward way to quickly get up and running with a Pyramid / Cornice webapp.
Do the JSON resources support complex relational models?
The built-in persistence layer is relatively simple and should fit almost any use case where the data have no particular relationship; however, you could take advantage of the full power of the protocol by using a custom Collection class to manage these relations.
As an aside, this might be a good excuse to implement the protocol within the Django REST framework. :-)
Is it possible to do XYZ?
We'd like to prepare a series of recipes and tutorials, but for that, we need to collect idea from the community. Some potential ideas include:
- Hooks for GitHub authentication.
- Modifying the JSON logging format.
- Storing mapping (topographical, geo, etc) data.
Can Cliquet deal with files?
No. Well, not yet at least.
We're holding off until we have a concrete need for this functionality at Mozilla. Should file storage become a thing, it would likely use Remote Storage in order to hook into that growing ecosystem.
Will feature XYZ be implemented?
Cliquet is already quite well stocked with features. In general, rather than implementing new functionality, we'd rather work on ensuring that the base abstractions and extension mechanisms are robust enough to allow for a diverse plugin-style ecosystem.